
This is an archive page. What you are looking at was posted sometime between 2000 and 2014. For more recent material, see the main blog at https://laboratorium.net
The Laboratorium
August 2009
GBS: Filings Roundup for Monday, August 31
- CDT requested and received permission to file an amicus brief on privacy issues.
- The German government filed objections to the settlement, on the grounds that it contravenes German, European, and treaty law. (Civil procedure note: the brief describes itself as an “objection,” but the government appears to be proceeding as an amicus curiae rather than as a class member.)
- A coalition of publishers and publishing industry organizations from Sweden, Switzerland, German, and Austria filed a fierce objection, claiming badly deficient notice and violation of the Berne Convention, among other things.
The Onion: Facebook, Twitter Revolutionizing How Parents Stalk Their College-Aged Kids
It’s a story about voyeurism, not exhibitionism. Brilliant.
GBS: Filings Roundup for Friday, August 28
Slow day Friday: only four new filings.
- Abilene Christian University supports the settlement. Their position is primarily as a consumer of books:
While interlibrary loan reduces the inequalities among libraries, there is a financial cost as well as a delay for scholars requesting the work, with no guarantee that an individual book will even be useful to their research. Thus, the settlement is a significant change for the better by creating a means for us to offer immediate electronic access to crucial published resources. [JG: Note that they want to rely on the Institutional Subscription to replace ILL; whereas UW-Madison pointed to print-on-demand as the ILL-killer.]
Arthur Ramous is staying in the settlement, but has comments (in a letter cc:ed to Barack Obama and Arne Duncan). Since “Google now becomes Keeper of the Knowledge … I would like to suggest that Google transmit the Google book data base electronically to the copyright office or to some other designated governmental office on a regular basis, say semi-annually or annually.”
Author Virginia Aronson objects via letter, complaining primarily to the poor royalties authors have been receiving. She writes, “Talk to almost any professional writer and you will hear the same sordid tales of unpaid and underreported earnings, remaindered titles, and copyright infringement.” She says that the settlement “will make writing books an act of masochism, guaranteeing that authors will never be paid for their time and effort,” though she doesn’t elaborate on how the settlement is worse than the raw deal authors are currently getting.
Author Erika Mailman objects via letter as well. She regards Google as “an interloper who had nothing to do with the writing of my books, nor the publishing of them.” She’s furious that Google’s share of the money will be larger than authors’. She also sees the settlement as undermining both e-books and the library system.
GBS: Interesting Points from UW-Madison’s Letter
The University of Wisconsin at Madison is a Google scanning partner and was one of the first libraries to sign an amended agreement after the settlement was announced. Their letter supporting the settlement says a few things that haven’t been said before.
The letter invokes the Wisconsin Idea, as articulated by UW-Madison President Charles Van Hise in 1904, when he said he’d “never be content until the beneficent influence of the university reaches every home in the state.” It’s nice to see a library articulating its public mission to make its collections as broadly available as possible. Other publicly minded librarians have reached different conclusions, but UW-Madison does a good job of connecting its view of the settlement to its fundamental principles.
The letter mentions some of the library’s special collections that are being digitized, including genealogical materials and its Native American and African American collections. These details give the letter a specificity that’s been missing from some of the other letters in support.
I also found this paragraph noteworthy:
This aspect of the settlement [print-on-demand, one of the optional New Revenue Models] could also alter or eliminate the traditional interlibrary loan process. In the end, it may be more effective, in respect to both cost and time, to buy a single print copy on demand than to borrow and ship a copy from another library, resulting in additional fair compensation for the authors and publishers.
I’m sorry I couldn’t make it to the Berkeley conference on Friday. It seems like a fascinating day; the panels managed to get away from the legal details and delve into some of the very hard policy issues. The video, I’m told, will be online within a couple of weeks. Until then, for a general conference wrap-up, here’s a collection of links to stories about it.
The most interesting panel of the day appears to have been the “information quality” one. It was moderated by Paul Duguid, who’s written a very thoughtful piece on scanning quality, and it featured an absolutely scathing presentation by Geoffrey Nunberg on the atrocious metadata to be found in Google’s catalog. He’s concerned that Google will have the “last library” (whereas I see my job as making sure that there will be others), and thus, he’s concerned that our universal library will have howlers like an edition of Bonfire of the Vanities from 1888 and books on the Internet from 1905. Don’t even get him started on cataloguing Tristram Shandy as “Biography and Autobiography.” His post at LanguageLog, A Metadata Train Wreck, gives the argument in some detail and responds to some of the objections raised by Googlers.
Relatedly: Google Turns Classic Books into Free Gibberish eBooks.
Washington Post: Soul-Searching on Facebook
The subhead is “For Many Users, Religion Question Is Not Easy to Answer,” and I found this passage on technical affordances striking:
The religious views box made its debut in 2006, two years after the launch of Facebook. Before that, users who talked about faith mostly did so in the “About Me” area.
The company had tried a political views box with a drop-down menu of limited choices. The religious views box, however, was created with one key difference: a free-text format that let users type in whatever they wanted. (It proved so popular that Facebook later made its political views box free-text as well.) By contrast, MySpace, another popular social networking site, also offers a religion box, but it’s a drop-down menu limited to 14 choices.
Since then, Facebook’s beliefs box has generated a staggering number of entries. So exactly how many users put down “beer” as their religion? How many “Catholic”? What correlations exist between religion and number of friends?
Or consider one user’s experience:
For Heim, who joined Facebook last year, the box posed a question with no easy answer.
With space limited to 100 characters, there was simply no room for Heim to go into his childhood experiences with faith — growing up with an agnostic father, an evangelical mother and a fundamentalist grandmother. There was no space to describe the terror he felt after learning of heaven and hell. Or how the hell part weighed especially heavily after he was caught breaking into a neighbor’s home at age 7.
He couldn’t convey the profound faith and forgiveness he found in junior high after hearing the tear-filled sermons of a charismatic Baptist minister. Or the eventual dulling of that faith in college by alcohol. And he couldn’t fully explain the slow reformation of that faith, now that he has abandoned the hollowness of his old party life.
“How the heck do you fit all of that into a box?” asked Heim, who sometimes attends a Lutheran church in Dale City.
So rather than type in a specific denomination or a pithy, amusing answer, Heim entered this non-sequitur: “Colorless green ideas sleep furiously.”
It is a phrase written by linguistic philosopher Noam Chomsky to demonstrate how a sentence can be grammatically logical and yet have no meaning — how things that seem so right at first can crumble under scrutiny.
“It represents my faith,” Heim said, “how it sometimes makes sense to me and sometimes doesn’t.”
The religion box, like the other elements of a Facebook profile, is simultaneously performative and constitutive.
GBS: A Reply to Hausman and Sidak
As I noted last week, Jerry A. Hausman and J. Gregory Sidak recently published Google and the Proper Antitrust Scrutiny of Orphan Books. Their basic model is that Google Books will be a “new good” coming on the market. New goods benefit both the firms who sell them and the consumers who buy them. The prospect of those profits is an incentive to introduce new goods. Thus, the government needs to be careful to avoid stepping on the profits that pull new goods into existence. (If this reminds you at all of the arguments for intellectual property, it’s not a coincidence; Hausman and Sidak mention the role of patents as a source of incentive-producing exclusivity.)
According to Hausman and Sidak, if antitrust investigations have the effect of regulating a previously unregulated market, it hurts incentives by allowing other firms to grab shares of the incentivizing profits, or even to compete them away. Antitrust can also hurt slowing down the introduction of a valuable new product. Thus, antitrust actions should be saved for situations in which the first entrant will have harmful market power. In this case, however, Google won’t. Competitors would face no legal barriers to entering the market as Google did: by scanning books themselves. Thus, there are substantial costs to antitrust intervention, and no offsetting benefits, so the Antitrust Division should stay out and let the settlement go through.
I see three important assumptions in here:
- Competitors won’t face legal barriers to entry.
- Google Books will be a new good.
- The relevant market is currently unregulated.
All three are false, and for the same reason: copyright. The orphan works are existing goods created by copyright law; the market for them is pervasively regulated by copyright law; competitors will be unable to enter without violating copyright law.
In the rest of this post, I’m going to analyze these three assumptions to show where I think Hausman and Sidak go wrong. This won’t be a comprehensive reply to their paper, although there there are other issues they also get wrong, as well as issues they get right. I want to focus on what I see as their fundamental problem: a failure to work through the copyright issues that are intertwined with the antitrust ones.
GBS: I Don’t Understand EU Politics
This article on the conflicting stances taken by EC Commissioners has a lot of useful information in it, but it also points up the difficulty of identifying any official EC position. And passages like this one make my head hurt:
The issue currently forms part of the internal market portfolio, but a likely reshuffle of competencies within the Commission could put it in the hands of a stronger information society commissioner, a situation coveted by Reding.
However, France is fiercely fighting for the internal market portfolio, which currently also includes the hot dossier of financial services.
Depending on how important the EC’s actions become, I may need to go immerse myself in some kind of EU law primer. Anyone have a time-turner I could borrow?
A World Being Taken Over by Amateurs
The fact that single, unique recordings were replacing multiple performances of songs meant that record companies were becoming more interested in quirky, one-off records and less dependent on reliable studio performer—which is to say it encouraged the deprofessionalization of pop music. A street-corner doo-wop group could get a top-ten hit while still in high school without making any professional appearances, knowing more than a handful of songs, or understanding the intricacies of union regulations, record royalties, or publishing contracts. So a lot of the resistance to rock ‘n’ roll within the music business can be traced to professional musicians, songwriters, and arrangers worrying about their futures in a world being taken over by amateurs.
—Elijah Wald, How the Beatles Destroyed Rock ‘n’ Roll: An Alternative History of American Popular Music 177–78
GBS: On the Open Rights Group’s Letter
The Open Rights Group is a kind of loose U.K. analogue to the EFF, standing up for online civil liberties against ill-informed laws. The differences are partly organizational: the ORG does mostly grassroots activism, whereas the EFF also litigates. They’re also a bit cultural: the ORG is somehow, indefinably, British in its style.
In any event, the ORG has filed comments on the Google Book Search settlement with the European Commission for its upcoming hearing. The EC is in an interesting position. On the one hand, it (along with its member states and EU locals) could try to block the settlement from going into effect. Yes, the settlement purports to be U.S.-only, but one might argue that it has extraterritorial effect, or that it prejudices the interests of foreign copyright holders in violation of international treaty law. If they acted on a coordinated, EU-wide basis, they could probably put enough pressure on Google to block the deal. (It’s the LICRA v. Yahoo! principle all over again.)
On the other hand, the EC is in some ways in a much freer position to act than the court in the GBS case is. As a legislative body, it can take the synoptic view and create a solution that takes everyone’s interest into account, rather than being bound by the strictures of class action law. (One could argue that it’s only the relative looseness of U.S. class action law that tempted the parties into going that route, rather than the more legitimate legislative one.) Indeed, that seems to be the tack the EC may be taking, considering changes to its copyright law to promote Google Books-like private solutions, quite likely including Google Books itself, but also open to competitors and nonprofit institutions on equal terms. (Then again, reading the questions for public consultation more closely, perhaps copyright reform itself is off the table. I don’t know the EC structure well enough to know for sure what’s going on.)
This is the backdrop against which the ORG writes, and its comments can only be understood in this context. The proposals themselves would often be inappropriate as arguments at the fairness hearing, but they make sense as input to the EC. ORG’s overall position is one of moderation: “ORG does not make a general objection to the proposed Settlement, but calls for clarification and amendment where appropriate … .”
The first major heading is privacy. Unlike the U.S. commentary so far, which focuses on substantive privacy threats, the ORG focuses on the EU legal framework, explaining to the EC why it should take a proactive role. It endorses the EFF’s privacy requests and essentially urges the EC to institute privacy protections by law unless Google shapes up and commits to them directly.
The second heading has to do with DRM. Of course, the entire Google Book project (for in-copyright books, that is) will be one of those cloud-competing services that are all but indistinguishable from DRM. For the ORG, this is a consumer rights problem, along the lines of the Berkeley conference from two years ago.
The third heading has to do with international development and the spread of knowledge. The ORG starts off by stating:
There is a problematic asymmetry associated with the inclusion of European works in GBS, but with no statement from the promoters of the project as to the availability of those works, or the works from any other jurisdiction, including the US, to European readers, and to readers around the world. At the very least, the Commission should question why US students, researchers and indeed purchasers should be able to access close to the entire corpus of the European written word, but European equivalents unable to gain access to European, US or other material. Paradoxically, this Settlement would mean that US-based researchers would have much greater access to out-of-print European works (defined as not commercially available in the US, which is important) than Europeans.
Note what a great point this is from an access-to-knowledge perspective, but how absurd it sounds if you have your head wrapped up in the class action litigation. European authors are complaining that the U.S. program will leak, undercutting domestic markets—but here’s the ORG saying that it ought to be just as available in Europe as it is in the U.S. In some ways, this is a classic copyfight, pitting copyright owners against open access advocates. And note that Google, which would love to expand the program beyond the U.S., enters this fight on the side of the open access advocates again. Again, the legislative character of the EC inquiry comes to the fore, as the ORG explains that “the Commission should see this aspect of the Settlement as having notable implications for matters beyond the strict application of international copyright law. “
Finally, the ORG takes up orphan works. Here, the ORG takes arguments that U.S. settlement followers are probably sick to death of, and puts them briefly in a European context. Thus, the ORG first sounds the alarm about the prospect of a Google monopoly:
As this Settlement is between private parties, others wishing to engage in conduct similar to that of Google will not be able to rely on the Settlement as a precedent, but will instead need to act as Google did - await the bringing of suit in similar terms to the original case against Google - and presumably seek a settlement or await trial for alleged copyright infringement. Therefore, the barrier to entry is a very high one. Google will, in accordance with the Settlement, have a licence that others cannot, without engaging in expensive negotiation or litigation, avail of, and of course for orphan works, such negotiations are impossible in many cases, and therefore others will have no assurance that they can ever be licenced to compete, putting them at an immediate and perhaps irreversible disadvantage.
Actually, I think the ORG could have gone even further here. In the U.S., we’re arguing over the parameters of U.S. class action law. I should think that the EC would have more right to be skeptical about how U.S. class actions might work. Assurances that others could do the same as Google has done and get similar settlements strike me as something that foreign regulators might be disinclined to believe on institutional grounds.
Next, the ORG reminds the EC that even if the settlement goes through, it’s not a full solution to the orphan works issues. Google, of course, would agree. In its policy-making role, the EC could of course also consider whether the settlement will make solving the orphan works issue in other ways more or less difficult, and the ORG asks it to. The letter closes with a suggestion that the Google Book collection could become an essential facility under antitrust law. I don’t know whether that doctrine is more viable in Europe than it is here, but the European antitrust regulators have indeed been more aggressive than their U.S. counterparts in recent years.
Three stories from the last few days are importantly related. When Google added EPUB support to their public-domain book downloads, it was a good move for open access. EPUB is an international, open standard supported by many brands of e-book readers. Sony—which is about to file an amicus brief supporting the settlement—uses EPUB on its Reader. Meanwhile, Amazon—which is about to file objections—uses its own, proprietary file format on the Kindle.
All three companies will have legitimate legal points to make, of course, but one mustn’t neglect the commercial power politics behind their choice of positions.
GBS: Big Day on the Docket Sheet
With just a week to go before the filing deadline, there’s a lot happening on the docket:
- Sony wants to file an amicus brief in support, since they think the Google Book project will boost e-reader sales. Not yet mentioned: the Google-Sony partnership on public-domain e-books on the Sony Reader. Unlikely to be mentioned: in the book space, they have a mutual foe in Amazon. Sony is represented by Silicon Valley powerhouse Cooley Godward.
- Speaking of Amazon, copyright heavyweight David Nimmer filed for admission pro hac vice on their behalf. Nimmer works out of L.A. powerhouse Irell & Manella and, of course, is the editor of Nimmer on Copyright. With Patry working for Google, all we need now is for Paul Goldstein to get in the game, too, for a battle royal of the copyright treatise-ists.
- The Samuelson Clinic at Berkeley and the EFF jointly started the process of intervening on behalf of authors who object to the privacy provisions (or lack thereof) by filing motions to admit their lawyers pro hac vice.
- Meanwhile, the University of Wisconsin at Madison and the Association of Independent California Colleges and Universities filed letters in support of the settlement, and authors Yin-Po Tschang and Sallie Lowenstein submitted letters opposing it.
All of the relevant documents are in the pipeline for upload over at the Public Index.
I’m happy to announce that the conference website for D is for Digitize is live at http://www.nyls.edu/disfordigitize
We’ve got a great lineup of speakers, including a keynote conversation featuring academic heavyweights Paul Courant and Pam Samuelson.
What’s more, registration is now open, so sign up early and sign up often.
Lots is happening. Today (thus far):
- The Open Rights Group became the first organization to come forward with comments to the European Commission’s upcoming hearing on the case. The international perspective they push is very interesting, because the procedural posture is so different. Here in the U.S., we have a pending case before a court and the issues turn on legality; there, matters are comparatively much more policy-oriented. (It’s not immediately obvious whose position this shift favors.)
- Bernard Lang posted an updated version of his essay on the international angles.
- Jerry A. Hausman and J. Gregory Sidak published Google and the Proper Antitrust Scrutiny of Orphan Books in the Journal of Competition Law and Economics. They join Mark Lemley, David Balto, and Einer Elhauge as antitrust anti-critics.
- Google Books added support for the EPUB file format for its public-domain downloads, making for yet another open-access-friendly policy announced in the days leading up to the filing deadline.
- The Open Book Alliance unveiled its website opposing the settlement. As expected, Gary Reback and Peter Brantley are running it, on behalf of an interesting coalition of Google competitors, authors’ groups, and library groups.
Joseph S. Hall, of Kellogg, Huber, Hansen, Todd, Evans & Figel has entered an appearance in the Google Book Search case. At first, he said he’d be representing the Authors Guild, but then the clerk’s office added the cryptic notation “FILING ERROR - DEFICIENT DOCKET ENTRY - (WRONG FILER SELECTED).” Instead, he filed an appearance on behalf of a list of “putative plaintiffs’ class members that starts with Harold Bloom. Yes, that Harold Bloom. The list then rattles off a fairly impressive set of names (with a distinctly conservative overall tilt) from Elliott Abrams to John Yoo. There’s a distinct overlap with the list of clients of Writers Representatives, the firm of literary agent Lynn Chu, one of the most outspoken critics of the settlement.
I’d say we’re waiting for the other shoe to drop, except that there are so many suspended shoes in the air at the moment that it’s hard to say which one is the “other” shoe.
UPDATE: This particular shoe isn’t going anywhere until attorney Hall crosses his ‘t’s and dots his ‘i’s. The clerk’s office just added to the document the notation, “Note to Attorney Joseph Hall to RE-FILE Document [146] Notice of Appearance. ERROR(S): Each individual plaintiff listed on the Notice of Appearance must be added on to the docket.”
My analysis of Elhauge’s paper is going to be held up a bit. It’s not so much the fact that this is the first week of classes for me as that there are some important details that I want to get clarity on, and this may take a little while. I hope to have something posted next week.
Publishers Weekly conducted an online survey of readers to see how they felt about the Google Book Search settlement. Now the results are in. Some interesting numbers:
If there is good news for the architects of the deal, it is that net support for court approval outweighs opposition—overall, 41% of respondents supported approval of the settlement, while 23% opposed the deal. Just weeks before the September 4 deadline for opting out or objecting to the settlement, however, it is notable that more than a third (36%) remain unsure of or indifferent to the settlement. Publishers (52%) support the settlement in the greatest numbers, followed by authors (42%) and librarians (29%).
…
Notably, some 23% of respondents said they were unsure whether they had standing—hinting at the level of confusion surrounding the settlement.
…
Because they are a party to the suit and chief architects and proponents of the settlement, we also broke out the 86 respondents who said they were members of the Authors Guild—just under 10% of the entire sample. Not surprisingly, a higher percentage of Authors Guild members favored approval of the settlement (62%). Still, we were somewhat surprised that less than a quarter of Authors’ Guild members we surveyed “enthusiastically supported” the settlement (24%). Some 19%, meanwhile, opposed the deal—four brave members said they actually planned to formally object to the settlement.
…
Overall, a surprisingly high number (61%) said they planned to take no action at all—roughly a third (32%) said they will take no action while 29% said they haven’t yet decided if they will participate. That number is inflated, however, by respondents who do not have standing—because without works to claim, respondents have fewer options; they can file comments, but otherwise have no need to act. When limited to those with standing, participation levels rise considerably, but still not to high levels. Just over half of those with standing (55%) said they have or will register to assert their rights by the January 5 deadline—rights that include receiving a $60 payment from Google if their book has been scanned.
…
Perhaps the most surprising result came from a simple but provocative question: we asked whether respondents supported the filing of the initial lawsuits, whether they believed the scanning was fair use or illegal, or the suits were ill-advised or well considered—for whatever reason. Notably, less than half of all respondents (49%) supported the original lawsuits.
GBS: Einer Elhauge Says the Settlement is Procompetitive
Remember how I keep saying I’m waiting for a real antitrust analysis? It looks like Elhauge has written one. At 60 pages, this is going to take me a while to digest.
GBS: German Government to Oppose Settlement
They’ve hired Sheppard Mullin to draft an amicus brief expressing opposition. The NYT story is sketchy on the details, but it looks like they may hit the territoriality question.
Facebook Saved, Google Dilemma’d
Two articles I’ve previously blogged are now available in their final, published versions. Download them while they’re lukewarm!
The Google Dilemma, 53 New York Law School Law Review 939 (2009):
Web search is critical to our ability to use the Internet. Whoever controls search engines has enormous influence on us all. They can shape what we read, who we listen to, and who gets heard. Whoever controls the search engines, perhaps, controls the Internet itself. Today, no one comes closer to controlling search than Google does.
In this short essay, I’ll describe a few of the ways that individuals, companies, and even governments have tried to shape Google’s results to serve their goals. Specifically, I’ll tell the stories of five Google queries, each of which illustrates a different aspect of the problems that Google and other search engines must confront: “mongolian gerbils” shows their power to organize the Internet for us; “talentless hack” shows how their rankings depend on collective human knowledge; “jew” shows why search results can be controversial; “search king” shows the tension between automatic algorithms and human oversight; and “tiananmen” shows how deeply political a search can be. Taken together, these five stories provide a snapshot of search and the interlocking issues that search law must confront.
Saving Facebook (formerly “Facebook and the Social Dynamics of Privacy”), 94 Iowa Law Review 1137 (2009):
This Article provides the first comprehensive analysis of the law and policy of privacy on social network sites, using Facebook as its principal example. It explains how Facebook users socialize on the site, why they misunderstand the risks involved, and how their privacy suffers as a result. Facebook offers a socially compelling platform that also facilitates peer-to-peer privacy violations: users harming each others’ privacy interests. These two facts are inextricably linked; people use Facebook with the goal of sharing information about themselves. Policymakers cannot make Facebook completely safe, but they can help people use it safely.
The Article makes this case by presenting a rich, factually grounded description of the social dynamics of privacy on Facebook. It then uses that description to evaluate a dozen possible policy interventions. Unhelpful interventions—such as mandatory data portability and bans on underage use—fail because they also fail to engage with key aspects of how and why people use social network sites. On the other hand, the potentially helpful interventions—such as a strengthened public-disclosure tort and a right to opt out completely—succeed because they do engage with these social dynamics.
Towards the end of Ed Hasbrouck’s letter, he writes:
You can both object and file a claim, but if you do either, you are bound by any eventual settlement, even if you objected to the settlement terms. So there is a risk to objecting: If your objections are overruled, and the settlement is approved, you will be subject to the very settlement to which you objected.
I’ve been wondering about this for a while. It’s hornbook law that you can’t both opt out and object. I’ve confirmed this in Moore, Wright and Miller, and the Manual for Complex Litigation, all of which consider the point so uncontroversial that they pass over it quickly. Formally, the theory is that once you’ve opted out, you’re not going to be bound by the lawsuit, and thus you have no standing to object. Fine, and that makes sense when the opt-out deadline comes first. Here, however, there was never an initial class certification with out-out opportunity; instead, the case went straight to settlement. Thus, the opt-out opportunity and the objection opportunity share the same deadline, and thus, they’re incompatible, right? You see the same reasoning in lots of class action settlements.
Except that for people like Hasbrouck, this black-letter rule makes no sense. He thinks the settlement is bad for him and for people like him. But he faces a very unattractive choice. He can either protect his individual rights, or he can put his own rights at risk if he tries to protect others’, as well. The structure of the choice encourages him to be selfish. But in the class-action context, where the passivity of most class members is one of the basic facts of the universe, we want the Ed Hasbroucks of the world to file pro se objections that put serious issues before the court.
Would it be so ridiculous to allow a conditional opt-out? You’d file an objection, together with the reservation that if the court does not grant your objection, you wish to opt out. It’s straightforward, it’s implementable, it doesn’t prejudice the settling parties, and it puts all relevant information before the court. If you want a formalistic theory to justify it, say that you’re placing the objection deadline first by a few seconds. It’s not an open-ended opt-out window; you need to declare your full set of positions all at once. All it does is preserve rights appropriately; lawsuits require some risk, but settlements are supposed to be about the security of informed choice.
I would be grateful to any readers who can elaborate on this question, point me to cases in which it has been expressly addressed, or explain to me why my suggestion is either illegal or a bad idea..
More from the pipeline: last month, the Center for Democracy and Technology released a set of privacy recommendations. The EFF may have narrowed its focus to government data collection, but the CDT is taking a more comprehensive approach, drilling down on the kinds of privacy protections one would look for in any heavily used online service. As usual, let me call out salient passages:
The settlement deserves court approval because it will unquestionably provide a significant public benefit at a size and scale that is not otherwise likely to be replicated in the near term. (1)
CDT, like the ALA, believes in the principle of “approve, then improve.”
At a minimum, before the settlement is approved, Google should issue a set of privacy commitments that explains both its general approach to protecting reader privacy and its process for addressing privacy in greater detail as Google Book Search moves forward. Since further detail regarding privacy matters may need to be fleshed out over time as the services are built, the court should monitor implementation of these privacy commitments as part of its ongoing supervision of the settlement. Critically, this structure—a set of evolving privacy commitments with court supervision—does not require an alteration of the current settlement. (1)
This approach makes CDT’s recommendations easier to implement, but means that CDT is more dependent on carrots than on sticks.
Indeed, we believe that the adoption of a robust privacy framework here will set a high standard for other providers as the online market for electronic books expands. (4)
Witness the carrot. This one is specially designed to appeal to Google, which likes to say it can beat anyone in a fair fight, and which likes to present itself as a boy scout of a company
Shortly before the publication of these recommendations, Google posted a “Privacy FAQ” list to the GBS blog. CDT is pleased that Google has made such a public statement—and indeed the statement speaks to several of our concerns—but we believe that this represents the beginning, not the end, of discussions of reader privacy, and that an explicit commitment subject to court oversight is nonetheless required. (3)
Still, CDT isn’t just going to leave things up to Google’s good graces.
Providing such breadth of electronic access to so many published books will give Google an unparalleled view of people’s reading and information-seeking habits. By hosting the scans and closely managing user access, Google will have the capability to collect data about individual users’ searches, preview pages visited, books purchased, and perhaps even time spent reading particular pages. Whereas in the offline world such data collection is either impossible or widely distributed among libraries and bookstores, Google will hold a massive centralized repository of books and of information about how people access and read books online. (5)
That’s a nice overview of how both the digital transition and the scope of this project have privacy implications.
While the settlement agreement does not fully describe the types of data Google will collect, it does offer some indication. Detailed user information will be collected and used to differentiate among the services offered, to calculate payments to rightsholders, and to prevent unauthorized access to the scanned books. (5)
Ironically, the settlement’s only explicit treatment of privacy comes in negatives. It’s true that Google plans to implement the services in ways that are more privacy-friendly than the settlement’s floor, but that fact also underscores just how low the floor is. We’re talking subterranean.
The agreement does state that Google cannot be forced to disclose “confidential or personally identifiable information except as compelled by law or valid legal process” in the case of a security breach, but it does not address voluntary disclosure by Google. (6)
This being EFF’s big concern.
We recognize that because the implementation of the GBS service is not yet fully conceptualized, it may not be possible for Google to commit to every privacy detail now. We therefore urge that Google set out, with as much specificity as possible, a baseline approach to safeguarding reader privacy that it can commit to now, as well as a process for articulating further detail once the settlement is approved and Google begins to design the implementation of GBS. That process, and the detailed privacy practices that emerge from it, should be subject to court oversight. (7)
This sounds right. To the extent that Google says it can’t make privacy promises yet because it hasn’t designed the system, I fear a whipsaw. Google controls the timing and contents of the settlement, and the timing and features of its services. It’s awfully convenient that the service “is not yet fully conceptualized” in these pre-approval days. But Google still has the chance to make things right on the privacy front; baselines, process, and court supervision should satisfy everyone’s concerns.
We believe that Google should clearly and prominently disclose the following… (8)
Notice, notice, notice; honestly, this matters more so that groups like CDT can be watchdogs than because users will read even the most prominent of privacy policies.
Thus, CDT believes that Google should commit to collecting only the data necessary to provide the services laid out in the settlement. For example, Google generally does not need to collect details about how readers are consuming its digital books—which pages they view, how often they view them, how long they view them, and so forth—and thus the default should be that it will not do so. (8)
Modulo concerns about security (e.g. watching for telltale signs of botnets, DDoS attacks, hacking attempts, and the like), makes sense to me.
Google, however, should have no need to know the identity of any individual user of an Institutional Subscription, only that such a user is authorized under the subscription. Institutions should therefore be responsible for authenticating their own end users without sharing authentication credentials or other personal information with Google. (9)
This matches my understanding of what Google plans to do, and thus should be no problem to commit to.
Given the potential sensitivity of information surrounding reading habits, Google should refrain from using information collected through GBS for purposes other than to provide and secure the GBS service. (9)
When it comes to data that could reach third parties, it’s hard to emphasize this one enough. The terror of Scroogled turns on sensitive information being “repurposed.” The books you read are especially dangerous in this regard; just ask Winston Smith.
By default, information collected through GBS should not be used in connection with any other Google services or combined with data from other Google services, including advertising services provided outside the GBS site. (9)
Here, I’m less certain. I don’t so much care about combining this information with other Google services, provided the combination doesn’t open up leaks. I wouldn’t want information about your reading habits to be reconstructable from observing your customized searches, for example.
The Book Annotation feature may create especially sensitive user records because it involves users generating their own content and identifying other users with whom to share it. (9)
Right now, Book Annotations look “private” because they involved restricted, explicit sharing. But the parties have made noises about eventually opening up additional annotation features for broader distribution. Mark my words: as book annotations go social, there will be emergent privacy problems without clear answers.
Google has an obligation to state, in advance, what kinds of process it will comply with and what kinds it will resist. At a minimum, Google should state publicly that, except in cases of emergency or situations in which Google determines that it has little chance of prevailing, it will take reasonable steps in response to government requests to insist that the government obtain a court order or warrant issued upon probable cause to compel disclosure of information that could be used to identify a user or to associate a user with access to particular books. (10-11)
This one is easier for the time being because the settlement is U.S.-only. Some of the difficulty in articulating how strongly Google will resist stems from the enormous variety of legal systems around the world. In some, like China, a request can be unofficial but mandatory; in others, like Italy, official legal processes can be massively abused. For a U.S.-only deal, though, a unified policy is the kind of thing Google would need for its own internal operations and ought reasonably to disclose.
Because it is difficult to foresee exactly what types of requests will be made, and because experience with those requests might reveal the need for adjustments to these disclosure standards, Google should commit to making available to the public certain details about the compulsory disclosure of GBS information. Specifically, it should make public the number of requests by government and civil litigants for GBS usage or user-identifying data it has received, the types of information sought, the types of legal action underlying the requests, Google’s response to each request, and the types of information, if any, that were in fact disclosed. (11)
Again, this one is important for the watchdogs like CDT.
Google should therefore commit to retain data in identifiable form or in association with a reader identifier only as long as is necessary for the purpose for which the data was collected, and in any event no longer than 90 days. (13)
Sounds like a good idea, and I wish CDT good luck in getting Google to agree.
The settlement’s Security Standard outlines a comprehensive set of security and compliance requirements that Google must implement to protect digitized files, but no equivalent set of requirements to protect data about readers and their use of GBS. To the extent applicable (some requirements might be irrelevant to securing reader information, such as the requirement to watermark digital images served to users), we believe that Google should apply the same security standard to the data that it collects in connection with GBS. (13)
This is a simple, elegant, and eminently fair principle.
I look forward to seeing Google’s response to these recommendations.
The Tragedy of the Tragedy of Craigslist
Gary Wolf’s The Tragedy of Craigslist, in this month’s Wired, is full of both brilliance—
“I’m not interested in politics. I’m interested in governance,” [Craig Newmark] says. “Customer service is public service.”
… Universal search subverts craigslist’s mission to enable local, face-to-face transactions; it increases the risk of scams and can be exploited to snatch up bargain, giving technically sophisticated users an advantage over casual browsers.
—and idiocy—
On this site, contrary to every principle of usability and common sense, you can’t easily browse pictures of the apartments for rent.
…
But seen from another angle, craigslist is one of the strangest monopolies in history, where customers are locked in by fees set at zero… .
The article’s introduction asks, “Craig Newmark started a galactic garage sale with millions of users, a killer business model, and revenue to match. So why is the site such a wreck?” Wolf then suggests that Craig’s laid-back quirks-slash-principles keep him from caring about the fact that craigslist is a wreck. The article never takes seriously the the possibilities that craigslist went galactic because it’s a wreck, or that that craigslist is a wreck because it’s galactic. Wired seems to have it in for craigslist because craigslist is boring—but craiglist is only boring if you care more about spiffy Web 2.0-compliant glitz than about transformative services and sustainable communities.
GBS: Ed Hasbrouck Thinks Authors Are Getting a Raw Deal
I know that I’m using the word “interesting” a lot, but this open letter by Ed Hasbrouck justifies the term yet again. He’s an author—and an officer of the National Writers Union—and he doesn’t like the settlement. Like some other authors who’ve already spoken up, he thinks the payouts are way too small, given the range of copyright damages; he objects to going to an opt-out regime. I think this piece of the debate has achieved stasis, so I won’t bore you by repeating my disagreement.
What Hasbrouck’s essay adds to the conversation is a relatively detailed analysis of the Author-Publisher Procedures, which he sees as inappropriate for small-press authors and those who negotiated e-book rights with care. This perspective is partly informed by his comparison of the Google case to the case formerly known as Tasini and currently known as Muchnick. From an authors perspective these class actions do look quite similar: both are about unexpected electronic uses of a work for which no explicit permission was ever sought. I simply don’t know enough about the publishing world to assess the truth-value of many of his claims in Part 2; I pass along the link because I found them, yes, “interesting.”
GBS: A Small Point About Class Actions
After William Morris’s first letter to its members recommending opting out, the Authors Guild came back with a strong reply. That led William Morris to issue a second letter. This time, the Authors Guild didn’t issue an official statement or hold a conference call; it just did some interviews with the press disputing William Morris’s version.
I would like to dwell only on one specific point made by the Guild’s executive director, Paul Aiken. In an interview with Publishers Weekly, he said, “authors who don’t want to sue Google should stay in the settlement.” He’s right in the sense that the biggest benefit of opting out of the settlement (as opposed to opting in and Removing ones book) is the chance to win a lawsuit against Google. That’s the center of what you give up by settling. If you can’t actually pull off the lawsuit, then you have little to gain by retaining the right to sue. For most authors, that lawsuit would be impossibly expensive.
So Aiken is right in that sense, but keep in mind that this is one reason why we have class actions. There are many lawsuits that would be infeasible on an individual basis but become feasible with ten, a thousand, or a million plaintiffs who can share the costs (often shared on a contingency basis, to be paid out of the expected winnings). Just because an author wouldn’t, couldn’t, or shouldn’t sue Google doesn’t mean that authors, plural, wouldn’t, couldn’t, or shouldn’t. The Authors Guild chose to make this a class action, in part, so that authors could speak with one voice.
That kind of rolling-up of many lawsuits into one has obvious risks. Not all authors might want to speak with that voice. The lawsuit might be conducted (or settled) incompetently, or in a way that favors some authors over others. When you pile together in one boat for the lawsuit, you all become dependent on the skipper. And that’s why there are rules about class actions to protect class members. Those rules include things like fairness hearings, notice, and … opt-out rights.
And thus, that’s where the focus of the action will be in the next few months: the rules and implications of class actions. It’s the class action that elevates this settlement from being merely big to being remarkable. It’s the class action that magnifies the antitrust and privacy risks. It’s the class action settlement that invites close scrutiny by the court. And it’s the class action’s implications that are at the heart of the back-and-forth between William Morris and the Authors Guild. Keep your eye on the class-action ball.
GBS: PMA Likes Settlement, Wants to Apply Clone Tool
PMA, formerly the “Photo Marketing Association International” but now “The Worldwide Community of Imaging Associates, filed a letter supporting the settlement on Wednesday. It raises three arguments in favor of the settlement.
First, PMA apparently thinks along the same lines I do because they explicitly praise the settlement’s precedential value for other media:
When the Settlement was announced, PMA members reacted positively by stating that the photo imaging community, in which there are billions of images (works) for which clearance of rights is impossible or difficult due to obscure ownership or no ownership information at all, should consider replication of some of the Settlement’s key features.
Second, PMA (hearts) the Registry and wants one of its very own:
In the photo imaging community, no registry of photographs currently exists and none is on the horizon. In PMA’s view, the precedential value of a book registry could serve as a powerful stimulus for the creation of a photograph registry and a step toward the resolution of the current photographic image orphan works issue.
Third, PMA, which is in favor of orphan works legislation, doesn’t see the settlement as an obstacle. Slightly paradoxically, the PMA states:
[T]he Settlement does not — and should not — chill legislative efforts to enact orphan works legislation. … As long as there are huge quantities of works where authors and owners are not known or cannot be reached, like in the imaging industry, congressional intervention will be necessary. By eliminating visual images from the Settlement, the settling parties assured the existence of a huge remaining orphan works problem.
Having gone over these benefits to the settlement, PMA then ends up agreeing with the library associations that continuing court supervision would be a good idea (particularly because the settlement “may have precedential effect on other industries.”
I liked this letter. Of course, it doesn’t address many of the settlement’s issues, but no three-page letter could be expected do. What it does do is call attention to a few important aspects of the settlement of interest to the photographic community; then take a clear and novel position on them. PMA is engaged constructively in the dialogue about the settlement. In hindsight, it’s becoming increasingly obvious how important the four-month delay was, and how many voices would have been unheard had the filing deadline not been pushed back to the fall.
GBS: Scott Gant’s Attack on the Class
Scott Gant is an author, a partner at Boies, Schiller, and a self-appointed crusader against the settlement. This Wednesday, he filed a 47-page objection to the settlement. It is the most comprehensive and aggressive attack on the settlement to date; the issues it raises are the most fundamental that anyone has brought up in a submission to the court. His view is that the settlement—or at least the Revenue Models portions of it—is fundamentally unsalvageable.
Gant starts by framing the settlement as “fundamentally a commercial transaction” (5). Compare the framing in our amicus brief, where we call the settlement’s approach “prototypically legislative.” We both agree that the settlement’s complexity takes it out of the realm of ordinary class actions. But he focuses on the commerical rights involved, whereas we focus on the public interests. This is a classic duck-bunny problem; both perspectives are valid. Indeed, if you don’t recognize both components, not only will you miss important dangers of the settlement, but you’ll also miss the reasoning for it in the first place.
Notice Trouble
Others have called attention to notice problems, most notably the literary estates represented by Andrew DeVore. Gant, however, uses them to go for the jugular.
He starts from a familiar slogan in class action law, “Individual notice must be sent to all class members whose names and addresses may be ascertained through reasonable effort,” quoting from the famous Eisen case. Eisen involved a class action over stock-trading commissions; the six-million-member class contained about two million members whose names and addresses could be extracted from the defendants’ teletype records. The Supreme Court rejected the plaintiff’s attempt to avoid sending them individual notices, even though he made a convincing argument that it would be so prohibitvely expensive as to end the lawsuit. The notice rules have something of a fiat justitia ruat caelum flavor about them.
Gant himself never received individual notice, and to all accounts, neither have many other authors. He points out that the Copyright Office has records of copyright registrations, and thus “all of the authors of the works at issue in this case are known or knowable.” (16) Actually, this isn’t quite true; foreign works need not be registered to be in the settlement. Gant’s point, however, stands, because it still applies to the subclass of United States works, which are registered.
In a bit of extremely clever jiu-jitsu, Gant also quotes the studies that Google and the Authors Guild pointed to to argue that there are relatively few orphan works. If it’s possible to find authors with a moderate search in the orphan context, he asks, how can the parties justify not having found authors in the class notice context? He does a similar trick with the claims made about how effective the Registry will be in tracking down rightsholders.
I think this is a powerful argument, but it doesn’t strike me as conclusive. The unexamined term in Gant’s brief is what level of effort is “reasonable.” Note that in Eisen, it was only the two million class members whose teletype records were right at hand who mattered, and that all that was at issue was whether to send an envelope to the last-known address. Gant wants to hold the parties to the higher burdens of tracking down all authors, to carrying out searches that involve more individualized investigation, and to ensuring that the letters actually reach everyone.
My guess is that the notice program was designed to comply with Eisen’s specific requirements. Gant starts off by speculating that “hundreds of thousands, if not millions” (15) of authors didn’t receive notices. By the end of the section, this speculation has become a dead certainty: only a “small fraction of the millions of class members were directly contacted through individual notice.” (22) While the individual mailings weren’t great, I know of enough authors who received them that I doubt things are so unambguously inadequate as Gant claims.
That said, however, this is an area in which even if Gant loses on a bright-line rule, he can fall back to the underlying standard of fairness. He raises arguments about the complexity and size of the settlement and its massive implications for class members. Arguments of this sort should be familiar from our amicus brief. Gant uses them to call for a searching inquiry into the quality of notice. Thus, he turns to the Summary Notice mailed out to authors.
Gant quotes its opening paragraph, correctly noting that it doesn’t say anything abut future claims, only past actions. Thus, he argues that authors whose books have not yet been canned will stop reading right there. His claim that the Summary Notice is misleading depends on this argument, because the very next paragraph opens by saying that the settlement, if approved “will authorize Google to scan in-copyright books.” (emphasis added). I think he’s right that the Summary Notice is unclear and doesn’t make it obvious that the settlement deals with future book sales, but I’ve never in my life met a class-action notice that was clear. The courts have set that bar unfortunately low.
You Call This Fair?
Gant’s strongest arguments, I think, concern his attack on the settlement’s economic terms, though he opens on a weak note. He contrasts the $60 cash payments with jaw-dropping $750 to $150,000 range of copyright statutory damages. Had the case gone to trial, though, the plaintiffs wouldn’t have gotten even $750 a work. They’d have gotten nothing. Google’s scans were fair use for the indexing purposes for which they were used, and $60 a work is a fair and reasonable compromise of that long-shot lawsuit.
He’s on firmer ground raising difficult questions about the Registry. He raises the quite realistic possibility that the Registry will not be economically viable—in which case, participants in the settlement will receive nothing from the forward-looking revenue models. Moreover, he asks what the Registry’s overhead will be and how authors can trust that they will actually see most of their 63%. At the very least, the parties ought to be required to give a clearer accounting of why they expect the Registry’s operating expenses to be acceptably small.
His complaints about the Author-Publisher Procedures are also likely to resonate with many class members. The settlement doesn’t so much look to ascertain who owns the appropriate electronic rights as it does allocate them by fiat. This is, in essence, a side deal between authors and publishers, one that replaces the messy diversity of contacts with a few standardized ones. I like that; it cleans up an anticommons and makes it easier for books to reach paying publics. But I can also understand why some authors don’t like it, particularly those who gave more thought to negotiating electronic rights. I would love to see a detailed walk through the Author-Publisher Procedures that tries to find the worst-case and average-case scenarios for both sides.
Gant’s analysis of the role of the Authors Guild is very sharp and is the most original part of the brief. He observes that while the Authors Guild is named as an “Associational Plaintiff,” the motion for approval of the settlement does not “appear to advance the Authors Guild as a class representative” (35). The authors’ memorandum supporting the settlement focuses on the five individually named authors as “adequate representatives.” This fact is striking, because the Authors Guild has always been the public face of the lawsuit, and it played a central role in the negotiations. This gives Grant a good rhetorical basis for asking what role the Guild—as opposed to the five individual plaintiffs—played in negotiating the settlement. It also lets him raise some more familiar questions about how representative the Authors Guild is of authors in general and how good a deal it struck on their behalf.
Gant also emphasizes the increase in the class from the initial lawsuit—which defined the class in terms of the contents of the University of Michigan’s library—to the settlement—which defined the class in terms of all books. This expansion is one of the reasons some authors, particularly international ones, have been freaked out by the settlement. They had no particular reason to expect they’d be implicated by the settlement until they realized that the settlement class was so much bigger. People don’t like surprises.
I’d also point out that the switch moved the class from being enumerable to being open-ended. You could, in theory, write out the complete University of Michigan catalog, produce a list of authors and publishers, and try to track them all down. But when your class consists of all copyright holders of all books, there’s no way to create such a list, because there is no authoritative master list of books.
Within this immense class, Gant thinks that the Authors Guild and its pets don’t make for appropriate representatives. In our amicus brief, we point to the line between orphan and non-orphan works and suggest separate representation for the orphans. Gant adds another line of division: that between works scanned as of the opt-out date and those not yet scanned. The settlement does take account of the division—only the former are eligible for the $60 cash payments—but Gant argues that they have a conflict of interest, as the former would want to push for the pot of statutory damages at the end of the litigation rainbow. Thus, he seeks not two subclasses, but four, making up the full two-by-two matrix.
I continue to see the orphan works issue as fundamental, for all sorts of public-interest reasons. I’m less convinced by the alleged split between those whose works have been scanned and those who haven’t. Given the weakness of the copyright argument in the scanning itself, the same reasons that make $60 fair also make combined representation reasonable.
Who Can Be Against Trust?
The antitrust portions of Gant’s argument, although excellently written, largely rehearse arguments familiar from elsewhere. (Indeed, Gant attaches a number of the antitrust papers mentioned in this space as exhibits to his filing.) He contributes to the conversation by dropping a footnote suggesting that the right term of art in antitrust law for the Registry may be “joint venture.” He also picks up on Randy Picker’s “no-Noerr” argument with an analysis of the text of the settlement’s Bar Order’s antitrust implications.
Proving Too Much?
Gant makes a few arguments that strike me as implausible. He claims, for example, the settlement is impermissible because it would “transfer class’ members intellectual property rights to Google and its partners.” (10) This, he claims, would “alter the substantive rights of class members,” but the Federal Rules of Civil Procedure (including class actions) are not to “abridge, enlarge, or modify any substantive right.” (10)
This is wrong in two ways. First, it misuses copyright law’s idioms. Copyright distinguishes non-exclusive “licenses” from exclusive “transfers.” The settlement is quite explicit that it gives Google only a license, not any copyright ownership rights. Gant has things exactly backwards when he says that the settlement is a “transfer” of copyrights to Google, “in effect a license permitting specific uses of copyrighted works.” (4). (I and others have worried that the settlement is effectively exclusive, but that’s only the case for orphan works, and it takes more work to reach that conclusion. The switcheroo has the effect of making the settlement sound more dire for copyright owners’ rights than it is.
More seriously, Gant’s argument, if accepted, would strike down the Federal Rules themselves. Of course lawsuits affect substantive rights; that’s what lawsuits are for. Of course settlements affect substantive rights; otherwise, they’d be useless. Of course the Federal Rules provide a framework for lawsuits and settlements; that’s their job. The Rules aren’t supposed to affect substantive rights except by providing the procedural framework to adjudicate them. And that’s exactly what this lawsuit does.
Similarly, Gant overreaches when he argues that the court lacks jurisdiction to approve the settlement. He claims that the main elements of the settlement involve the compromise of “potential future claims” and therefore can’t be justified either as damages or injunctive relief. Thus, he concludes, the settlement violates the case or controversy requirement of Article III.
I looked into this idea when working on our amicus brief and rejected it. Google announced specific plans to scan every book it could. The act of scanning is a prima facie violation of the copyright of each class member (though it’s likely not ultimately an infringement). That’s sufficient to create a live case or controversy between Google and each class member — the test being whether the class member would face a concrete enough threat of scanning to be able to sue Google for declaratory or injunctive relief to stop it. (The only exception I could see would be for class members whose books are obscure enough — not in any partner libraries, perhaps — that the scanning wasn’t imminent.) Once in court, though, parties can voluntarily enter whatever settlement they want. Patent cases, for example, regularly end with the purchase by the defendant of a forward-looking license, which of course would release future claims of infringement. There cannot be a categorical jurisdictional bar on releasing claims for future conduct, as Gant’s argument would imply.
Indeed, try to imagine settling this very case in a way that didn’t involve releasing at least some future claims. Google has scanned copies of books on its servers. Every time it backs up those servers, it makes fresh copies of the books (in a complex database, to be sure, but everything is there). Those copies are prima facie infringements of the reproduction right. Google can’t implement useful search without making at least some copies on an ongoing basis. Any release that let Google run Book Search at all would need to waive some future claims. Gant’s line in the sand against future-claim compromises is untenable.
This is not to say that releasing claims for future infringements would not be problematic on other grounds. Because releasing future claims can leave class members worse off than when they started the lawsuit, any settlement that deals with future conduct requires especially close scrutiny. Here’s what we currently say in the amicus brief:
Second, the Proposed Settlement waives future claims by members of the Settlement Class. “The settlement of future claims has been viewed as an area where there is a need for increased judicial scrutiny … .” WRIGHT, MILLER, AND KANE, FEDERAL PRACTICE AND PROCEDURE § 1797.3. As the Supreme Court stated when rejecting certification of a class of plaintiffs exposed to asbestos, “Many persons in the exposure-only category [i.e. those with future claims] … may not even know of their exposure, or realize the extent of the harm they may incur. Even if they fully appreciate the significance of class notice, those without current afflictions may not have the information or foresight needed to decide, intelligently, whether to stay in or opt out.” Amchem Products, Inc. v. Windsor, 521 U.S. 591, 628 (1997). Here, members of the subclass of orphan work book copyright owners are, by their very nature as orphan work owners, unable to “decide, intelligently, whether to stay in or opt out.” Indeed, the orphan work book copyright owners are even less able to recognize and defend their interests than the future claimants in Amchem. The Proposed Settlement does not merely compromise future claims for past conduct, as in Amchem. Instead, it would release Google from liability for its future conduct: scanning books it has not yet scanned, and selling copies it has not yet sold. It is thus particularly inappropriate for this Court to waive the future claims of the members of the orphan work book copyright owner subclass without a searching examination to ensure that their rights are adequately protected.
There is a genuine concern here, but note the difference. The court should be concerne with the practical effects on the interests of class members, a fact-intensive and nuanced inquiry. It does not need to worry about the categorical jurisdictional bar that Gant advances.
A Few More Fine Points
A few other scattered details I found interesting:
Gant’s sleuthing confirmed that the case was never heavily litigated. The $140,000 in expenses incurred by the authors’ attorneys are, according to Gant, “a tiny amount for a complex case or a large class action — further suggesting no significant discovery or expert work occurred.” (3) He also found some gems in Google’s 10-Q filing, which splits the settlement’s $125 million into a $95.1 million “settlement portion” and a $25.9 million “commercial portion.” (8)
In footnote 25 on page 13, Gant expresses a takings argument not unlike the one in the conclusion of my Unprecedented Precedent.
Gant and lead author counsel Michael Boni are not good buddies. In footnote 27, Gant describes a telephone call he placed to Boni three weeks ago; Boni promised to call back, but never did. In footnote 85 (the final text of the brief), Gant takes his revenge, arguing that even if the settlement is approved, the $30 million set aside for the plaintiffs’ legal fees is excessive and should be reduced.
Conclusion
This is a very good brief. It is the best-written and sharpest filing I have seen in the case. Only the proposed settlement itself tops it in imagination. That said, are places where it goes wrong. I think, for example, that Gant shot himself in the foot by joining other, more persuasive arguments, to his unpersuasive treatment of the Rules Enabling Act. But even filtering out those concerns, this is still a smart and searching attack on some fundamental aspects of the settlement. How fundamental? Let me quote from the second-last footnote:
I take no position at this time about specific provisions of an alternative agreement which I might support. The issue before the Court is whether or not to approve this particular agreement. It is not the responsibility of the Court, or objectors, to rewrite the agreement.
In this, he’s actually allied with Google and the plaintiffs. In the past, they’ve responded to calls for modification of the settlement by insisting that this is an up-or-down call for the judge to make. Gant continues:
However, the Court might instruct the settling parties to decouple the two components of the Proposed Settlement — the resolution of claims for past infringement, and the commercial transaction involving the transfer of rights from copyright owners to Google and others. If the settling parties believe the terms of the commercial component of the Proposed Settlement are attractive, they are free to implement them outside the context of a Rule 23 proceeding, and invite copyright owners to participate.
Let us be clear. If the settlement goes down this path, the orphan works component of it is dead. That part works only because of the class action. In an ordinary negotiation, you can build an e-book service, but you can’t bring orphan works into it. That would be a great loss—not just for readers, but for society. And that is why I continue to believe that the goal must be to salvage this settlement, to take the flaws in it that Gant and others have identified, and fix them.
GBS: The Science Fiction and Fantasy Writers Aren’t Happy, Either
Somehow I missed this statement from the Science Fiction and Fantasy Writers of America when it came out. Their list of concerns with the settlement contains a bunch of familiar arguments, plus a few new ones:
The class representatives do not include any authors of adult trade fiction, an obvious issue for SFWA.
I’m not sure how finely one can slice and dice the class representatives (Scott Gant’s brief has some interesting things to say here about the Authors Guild’s role or non-role in representing authors), but the trade-publishing angle is one that may be noteworthy.
The class fails to consider fully licensees of works and fails to account for their interests.
I’m not sure what they’re getting at here, and would like to know more.
The terminology of the Google Book settlement makes no distinction, nor does it provide a mechanism for discovering the difference, between works deemed out-of-print and works in the public domain.
Unless they mean something other than what I think they mean, this strikes me as wrong. The settlement contains an administrative procedure to sort out claims over whether a book is public domain, and even provides for the potential recapture of revenues mistakenly paid over to the Registry for books that turn out to be in the public domain.
SFWA is not advocating a particular course of action nor providing legal advice for individual authors, who should evaluate the proposed Google Book settlement based on their own situation and with the advice and input of their own legal counsel.
For the record, SFWA believes that the proposed Google Book settlement is fundamentally flawed and should be rejected by the court.
That’s the strongest statement I’ve seen from a professional authors’ association.
GBS: Gillian Spraggs, Foreign Author, Does Not Like the Settlement
Gillian Spraggs, an English poet, translator, and historian, has written a essay expressing her opposition to the settlement. (She’s also a frequent Public Index contributor.) Her perspective is that of an overseas author shocked to find that what she thought an unrelated American lawsuit has swept her up in it. A few passages I thought notable, with my comments:
This project has taken me more time than I ever dreamed when I started it.
You and me both.
In the publicity given to the settlement in the press and on the web the phrase ‘US copyright interest’ has been widely used in describing the scope of the settlement. This initially led many non-US authors and rights-holders, including myself, to assume that the settlement would only affect their rights in works published in the United States. However, this is not the case.
Copyright law’s complexity has been a problem for everyone involved. The fraternity of experts who understand how international copyright law works is small indeed. The settlement has been complicated by the need to work around copyright’s territoriality rules. Now copyright owners are facing that complexity; even a perfect notice program would face the obstacle that the underlying law is hard to understand.
The sums that are promised are risible, far smaller than are normally payable for copyright licences. This is hardly fair payment; it is a pacifier for the desperate and the resigned.
Google would insist that the sums Spraggs cites—primarily the $60 per book digitized—aren’t licenses. They’re settlements in compromise of disputed infringement claims. You can claim your $60 and then exclude your book from any future display uses. A “license” wouldn’t be yours to keep in that way.
Here again, no regard is paid to the question of who actually owns the electronic rights to the work, or the US rights either. In the case of nearly all works published before 1987, and many that have appeared since, the electronic rights will not have been licensed to the publisher. Similarly, in the case of many books that have never been published in the USA, the US rights may also not have been licensed to any publisher. In such cases the Google Book Settlement Agreement is effectively making a bid to supersede and rewrite existing contracts: assigning to publishers rights that they did not previously possess and revenues that they otherwise would not receive. This quite unnecessary intrusion into existing contracts is a very disturbing feature of the settlement agreement.
This argument seems to be one of the ones that has really touched a chord with some authors and agents. The Author-Publisher Procedures may have been the closest the parties could come to a royalty-allocation scheme negotiated behind a Rawlsian veil of ignorance. All the same, it consistently seems to be the authors, not the publishers, who feel they got the short end of this particular stick.
The definition of ‘commercially available’ has caused alarm among foreign publishers, since it seemed to imply that books in print but not published or directly distributed in the US would be made available by Google to searchers (in preview) and customers (for online access), unless and until the rights-holders registered the works at issue with the Book Rights Registry and changed the settings, or applied to have them completely removed from the book corpus. However, following consultation with the lawyers who negotiated the settlement on behalf of the AAP, the Publishers Association of the UK has reported that Google plans to classify any book as commercially available if it can be purchased new from within the US through a website.
I hadn’t picked up on this point; it’s good to know.
The settlement agreement lays out the default pricing arrangements in considerable detail. It is open to rights-holders to specify their own prices, which the agreement states that only they can change. However, Google Inc. reserves the right to offer ‘temporary discounts off the List Prices from time to time at its sole discretion’. The payment to the Registry will be at the list prices ‘unless otherwise agreed by Google and the Registry’: in other words, it is always open to Google and the Registry to agree to pass the cost of any discount on to the rights-holders. This is an important point which has not received much comment and which in my opinion should ring alarm bells.
Much would turn on the quality of the Registry’s governance. I wouldn’t expect its board members to approve of such pass-alongs, but it is interesting that this power is reserved to them. I can see the argument for flexibility, but it would be useful if someone could point out the kind of scenario in which such flexibility would be necessary.
I even find myself wondering whether, so long as Google is pocketing the money from the ads served up next to search results, it may not be too worried either way by the success or failure of its venture into bookselling.
Que sera, sera. To the extent that the bookselling programs are flops, though, I suppose that rights owners and readers will be relieved from worrying about a concentration of power in Google.
Another security issue was raised in a point made from the floor at the Columbia conference. The participant noted that regardless of the fact that the complete Book Search corpus was only supposed to be accessible from within the US, people outside the US could use a proxy server located within the US to access the service. No one responded to his point. However, he is quite right.
Anyone who was present at the conference will remember the question, and would probably be willing to hazard a guess as to why the question was not answered. However, he is quite right. If the settlement proceeds, these porous territorial boundaries are likely to create substantial international pressure for local reforms to enable Google to implement its book search and sales programs in other countries.
The lack of representation of non-US rights-holders is troubling for many reasons. US and foreign authors and publishers cannot be said to have identical interests in the management of the Registry and the proposed operation of the book service.
One point that suggests itself concerns compliance. Since the digitised book corpus will only be accessible for commercial purposes within the US, foreign rights-holders who register will find it difficult to know whether their work is being used or excluded from use in accordance with the terms that they have stipulated. Moreover, they arguably have a much greater interest in Google’s taking steps to maintain territorial security; and there is no doubt that if Google is really serious about confining access to users within the US, determined measures will have to be taken (see above, Porous Territorial Boundaries).
This is the most concrete and forceful point I’ve seen made to date on the representativeness of the Registry’s board.
Many writers would find it repugnant for their work to be displayed alongside anti-gay advertisement campaigns. Many would also be repelled by anti-abortion campaigns. Some, of course, would be unhappy about ads for abortion clinics. Altogether, the rights-holders’ lack of control over the content of the ads that Google proposes to display alongside their work is a serious matter for concern.
This is a fascinating cultural question. I’ve had similar instincts; it’s one reason (among many) I don’t have advertising on my blog. No ads means no inferred endorsements. At the same time, because I use a Creative Commons Attribution license, I accept the possibility that someone will scrape my posts and use them alongside search-engine spam, domain landing pages, or other advertising material I loathe. I decided that I’d rather commit to open access, even open access for people I dislike, and that the presence of my CC-licensed words on a web page wouldn’t reasonably be taken to suggest I endorsed everything on that page. There are shifts of the meaning of authorship at work here, which raise important theoretical questions both in copyright and trademark law.
Article 16 of the settlement agreement mentions the right of either party to terminate the agreement ‘if the withdrawal conditions set forth in the Supplemental Agreement Regarding Right to Terminate between Plaintiffs and Google have been met’. However, it then states that ‘the Supplemental Agreement Regarding Right to Terminate is confidential between Plaintiffs and Google’.
The whole agreement, then, is subject to conditions that are being kept secret from the overwhelming majority of the settlement class. Authors and publishers are being urged by the promoters of the settlement to opt in to its provisions, but they are not being told all that they need to know in order to assess their best interests. This is yet another highly disquieting feature of the whole business.
Spraggs first made this point in comments at the Public Index, and I remain troubled by it.
Using information freely available on the web, I have investigated the origins and publishing histories of each of the plaintiffs. None of them originate from outside the US. (Two were born in New York City, one in Yonkers, one in Chicago, and one in Texas.) All have published mainly or exclusively in the USA. There is no representative here of authors from outside the USA, though the settlement class comprehends a very large number of non-US authors.
This is an interesting twist on her point about foreign Registry representation, above.
I would like to close by noting that I’m saddened that Spraggs’s essay links to the PDF of the settlement, rather than deep-linking to the individual cited paragraphs at the Public Index.
GBS: The Deep Breath Before the Plunge
The news is coming fast and furious.
Yesterday, D.C. lawyer Scott Gant, representing himself, filed an objection to the settlement, attacking the bona fides of the class action.
Today, it became public that a coalition of the Internet Archive, Microsoft, Yahoo!, Amazon, and unspecified others, has plans to file objections. The actual grounds are unspecified, but since Gary Reback is representing them, antitrust arguments are likely to figure prominently.
Also today, Ed Hasbrouck, frequent Public Index commenter, posted his analysis from a writer’s perspective. Earlier this week, Gillian Spraggs, also a Public Index regular, posted hers.
I am reading and blogging as fast as I can. All calls will be answered in the order in which they were received. There is a lot here to digest.
As with our section’s first call for papers in 2007, the theme of the submissions coordinates with the theme for the AALS’s annual meeting. The theme for the AALS’s annual meeting for 2010 is Transformational Law. Thus, the papers submitted should be related to the transformative nature of the law. Included in that broad category are any papers that suggest legal reform. Papers might focus on legal initiatives to help remediate the current economic crisis. Papers might more generally suggest legislative reform, policy initiatives, or particular judicial perspectives or interpretations. Papers might also focus on the intersection of law with other social sciences to better address needs and suggestions for social and political transformation.
GBS: The Urban Libraries Council Supposes the Settlement
The Urban Libraries Council (a “membership organization of North America ‘s premier public library systems and the corporations that serve them”) has filed comments with the court. Unfortunately, although notice of the filing is showing up on PACER, the comments themselves aren’t up yet. All I can link to for you is this HTML version at the ULC’s web site.
In broad strokes, their comments echoes those of their library brethren and sisthren at the ALA/ARL/ACRL: the settlement is a good thing, but we have reservations. When it comes to specifics, however, the ULC is more hard-hitting. After expressing concerns about privacy, pricing, and equity, the ALA brief asks only that the court exercise vigorous continuing oversight. The ULC, however, qualifies its “support” with requests “that the Court require the parties to address the issues raised in this document before approving the proposed settlement.” Those issues number four.
First, the ULC wants more library subscription options. They want an expanded Public Access Service, without the one-terminal-per-building restriction. To that, I can say only, “Ain’t gonna happen.” Unlimited in-library free access at all urban library systems strikes me as a dealbreaker for the copyright owners. The ULC’s position here reinforces my sense that the Public Access Service is a backfired attempt to win library support.
Less controversially, the ULC suggests expanding the Institutional Subscription so that the libraries can provide remote access. I see little trouble here. The Settlement explicitly provides for remote access to the Institutional Subscription for public institutions with Registry approval. Google and Registry also have a catchall provision allowing them to add new categories to the Institutional Subscription. If urban libraries want to buy remote access, Google and the Registry will doubtless be eager to sell it to them.
Second, the ULC wants reader privacy guarantees that match library records confidentiality laws. From what I understand of Google’s planned authentication model, this should be quite feasible. Google’s blog post on Book Search privacy says: “For example, people who use institutional subscriptions, such as students at subscribing schools, will not have to register with Google to read the millions of books available through the subscription. They only need to confirm their identity to the school’s system — not ours.” This ought to be an easy commitment for Google to make in whatever suitably binding fashion will make everyone relax.
Third, the ULC wants to protect first sale and fair use rights. The potential conversion of copyright’s permissive rules—sections 107, 108, and 109—into restrictive licensing regimes has been a big concern for libraries. The ULC’s proposed mechanism is interesting, and somewhat limited; they want limited free printing rights for their users. I wonder whether there will be librarians or others pushing for stronger affirmative reader rights.
The ULC also included the “public domain” in this section. As their letter states, “The proposed settlement provides for Google to collect a per-page charge for limited printing from the database, whether the book in question is covered by copyright or not.” I think that’s a misreading of the settlement. The {per-page fee](http://thepublicindex.org/archives/2819) for printing from the Public Access Service applies to “Display Books.” But “Display Books” is defined in terms of “Book.” And “Book,” in term only means a book still in copyright.
Fourth, the ULC wants public-library representation on the Registry’s Board. I doubt the parties will offer that, as such, but my (totally unscientific) hunch is that we’ll see some further announcement in the next month about the Registry’s governing structure. I wouldn’t be at all surprised to learn about a specific library “advisory board” or some such.
GBS: McCausland on Googling the Archives
One my students, Joe Merante (also a Creative Commons intern rockstar just called to my attention a very interesting article in the online law journal SCRIPTed:
Sally McCausland, Googling the Archives: Ideas from the Google Books Settlement on Solving Orphan Works Issues in Digital Access Projects, 6 SCRIPTed 377 (2009) (also available in PDF).
Many large scale digital archive access projects, whether undertaken by libraries, cultural institutions, commercial enterprises, research institutions or interest groups, struggle with orphan works and other copyright clearance issues. Under the default “opt-in” system prevailing under the Berne copyright treaty framework, each copyright owner must be located and give permission before their material can be digitised and made available for online uses. This imposes significant transaction costs and legal risks, and the public interest in access to cultural material is compromised. Various legislative solutions have been proposed, particularly in relation to orphan works, but no comprehensive solution has emerged.
Legal developments around Google’s activities in pursuit of its “Library Project” now offer new ideas. The Google Books Settlement is the provisional settlement of copyright infringement action brought against Google by the American Authors Guild and the Association of American Publishers. The case concerned the legality of the Library Project through which Google has digitised millions of “archival”, or out of print, books and made them searchable online. Google’s controversial defence to copyright infringement is that its actions constitute fair use under US copyright law. The settlement is not yet judicially approved and fairness hearings are set for October 2009. However, if approved, it will be groundbreaking. It achieves, via class action rules, a rule switch from opt-in to opt-out – creating a unique safe harbour for Google to commercially exploit millions of books without first searching for owners and seeking their individual permissions. In practical terms, it will vastly increase digital access to in-copyright, out of print books.
This paper considers whether legislative reform based roughly on this model could be applied to other digital access projects seeking to unlock cultural archival material.
McCausland provides a highly readable, fair-minded take on the intersection of the settlement, orphan works reform, and the Berne Convention. I wish I’d come across it before writing When the Unprecedented Becomes Precedent, as she anticipates some of the ideas I was playing with.
GBS: Pam Samuelson, Part II (Antitrust)
Her basic analysis will not be surprising to readers of this blog. Interesting points to note:
- Samuelson treats the relevant market as the “market for digital books.” (I’ve heard arguments for both smaller and larger definitions.)
- Consistent with her concerns about academic research and scholarly libraries, she focuses on the Institutional Subscription. (I’ve written more about the Consumer Purchase program.)
- Some the factors she cites when discussing whether that Google could monopolize the digital books market (or markets), such as Google’s five-year head start, may not directly matter at this stage. Given the general Section 2 rule that mere acquisition of a monopoly is not in itself unlawful, Google’s existing market position doesn’t seem directly relevant to the settlement. This is a reason that my own writing has had more of a Section 1 slant, treating the settlement more as an attempt by copyright holders to combine their rights. This isn’t to say that these other factors are irrelevant; if Google ever starts “price-gouging,” in Samuelson’s phrase, its head start would matter a lot in the analysis of how contestable the market is.
- This post is longer on analysis of possibilities and arguments and shorter on Samuelson’s own voice than her first post. The tone is scholarly, precise, and open.
- It’s been tweeted four times so far.
Steve Schultze WIll Be the New Associate Director of CITP at Princeton
Outstanding choice; like Ed Felten and the rest of the crew, Steve isn’t just smart, he’s clever.
GBS: Two More Letters in Support
The United States Distance Learning Association and United States Student Association have joined the chorus of pro-accessibility organizations favoring the settlement. In addition to the usual boilerplate about their organizations, the letters primarily reiterate familiar claims about the settlement.
The students get right to the point:
The settlement will dramatically expand access to millions of books through Google Book Search and other services that are enabled by the settlement. These services will have a transformative impact on research and scholarship, and will help level the educational playing field.
The distance educators are a little more dependent on jargon:
Approval will have a powerful impact on the critical issues of quality standards, research, teacher preparedness, and new technologies as well as the sharing and dissemination of the professional efforts and successes of professionals in all fields. Additionally, approval of the final settlement will increase and improve the educational resources of schools and universities that exemplify the dynamic nature of distance learning by expanding access to millions of books through Google Book Search and other services. These services will have a forceful impact on research and scholarship through distance learning. Moreover, approval of the settlement will support teacher preparedness and increase use of new technologies from kindergarten to the university.
If I’ve got this right, the impact will be “transformational,” “powerful,” and “forceful.”
Yesterday, the EFF released a news update boiling the privacy questions down to a single issue they see as overriding: government surveillance. Bookstores and libraries have fought hard for the principle that government can’t demand to know what books you’ve read without a search warrant. The EFF and its partner organizations want Google to make a similar commitment:
Given this backdrop, we asked Google to promise that it would fight for those same standards to be applied to its Google Book Search product. We want Google to promise that it will demand more than a subpoena (which is written by a lawyer and not approved by a judge) or some other legal process that a judge has not approved before turning over your book records. In essence, we asked Google to tell whoever came to them demanding reader information: “Come back with a warrant.”
The settlement, of course, is largely silent on privacy. Google’s position has been that it will apply the same standards to books as it does to web search, which can also be highly sensitive. Google’s current privacy policy provides:
We have a good faith belief that access, use, preservation or disclosure of such information is reasonably necessary to (a) satisfy any applicable law, regulation, legal process or enforceable governmental request, (b) enforce applicable Terms of Service, including investigation of potential violations thereof, (c) detect, prevent, or otherwise address fraud, security or technical issues, or (d) protect against harm to the rights, property or safety of Google, its users or the public as required or permitted by law.
The EFF, unhappy with the degree of discretion built into this standard, is now preparing to ask the court to order that a “Get a warrant or go home” standard be written into the settlement. Compared with the EFF’s original letter to Google, the frustrated tone of yesterday’s note is quite notable:
Honestly, we thought it would be an easy thing for Google to do.
Unfortunately, Google has refused. It is insisting on keeping broad discretion to decide when and where it will actually stand up for user privacy, and saying that we should just trust the company to do so. So, if Bob looks like a good guy, maybe they’ll stand up for him. But if standing up for Alice could make Google look bad, complicate things for the company, or seem ill-advised for some other reason, then Google insists on having the leeway to simply hand over her reading list after a subpoena or some lesser legal process. As Google Book Search grows, the pressure on Google to compromise readers’ privacy will likely grow too, whether from government entities that have to approve mergers or investigate antitrust complaints, or subpoenas from companies where Google has a business relationship, or for some other reason that emerges over time.
We need more than “just trust us” here. EFF has spent the last three years suing AT&T because that company decided, for reasons we still don’t know, that it would not stand up for user privacy when the government came knocking.
In in the past Google (unlike some other large search companies, *cough*cough*) has actually gone to court to fight governmental demands for search queries. In that case, though, Google’s arguments were longer on the trade-secret angle and shorter on the user-privacy angle. (Google did argue that if users felt their privacy was being violated they’d be less likely to trust Google, which is a kind of second-order privacy claim.)
Google’s attitude strikes me as interestingly Christian. Their corporate ethos—captured in the “Don’t Be Evil” slogan—is strongly committed to the idea that there is an objective right and wrong and that the company has a duty to do good. But they’re also committed to the idea that they should be bound by God’s laws, not by man’s. When faced with a moral dilemma, the Googlers withdraw to their cave for prayer and fasting to consult their inner lights, then emerge with the confidence of one through whom God has spoken. Where positive law and divine law conflict, the positive law must be the wrong one. Google will live with it, as a dutiful believer must, but will never accept its moral legitimacy. Indeed, to wrap Google in too many laws is to deprive it of the free will necessary for its moral choices to do good to have true meaning.
Maybe that’s a stretch. But I do have a sense that the EFF/Google rift here is about something slightly less clearly cut-and-dried than the usual public-interest/private-corporation divide. The EFF’s post sees Google as in constant danger of lapsing into sin, a view that is nearly incomprehensible within Google’s quasi-messianic narrative of itself.
Enough armchair psychoanalysis. Back to the docket and the clippings …
In modern societies, a public is by definition an indefinite audience rather than a social constituency that could be numbered or named.
—Michael Warner, Publics and Counterpublics 55–56 (2002)
Back in April, when the Internet Archive and two Berkmanites, Harry Lewis and Lewis Hyde, wrote letters asking for leave to file motions to intervene in the Google Book Search case, the District Court treated their letters as actual motions to intervene and denied them in a single paragraph. The Internet Archive went silent, but the two Lewises filed a notice of appeal to the Second Circuit. Presumably, they planned to litigate their right to be in the case.
I see today that the appeal has been withdrawn. One interpretation is that they’re giving up and will sit this one out. Another is that they plan to file a full motion to intervene, rather than just the preliminary letter they submitted last time. If I had to guess, I’d guess the latter.
The Bibliothèque Nationale de France is apparently about to sign a deal with Google that would merge the BNF’s book-scanning effort into Google’s own. This would mark the end of the most concerted resistance to the Google scanning project. The BNF’s former director, Jean-Noël Jeanneney, was a fierce Google critic, wrote a book attacking the Google Book Search project as a grave threat to non-Angolophone culture, and launched the BNF’s own scanning project. Thus ends one of the stranger oppositions to Google Book Search.
Now, there may well be a role for a “public option,” as Frank Pasquale would call it, in book scanning. Libraries, particularly the Library of Congress ought to take the lead (and be given more legal room) to produce preservation-quality scans. Greater library involvement could do good things for privacy, pricing, and competition. July’s Berkman conference was in large part about public values and public involvement in book scanning, search, and distribution.
But whatever a well-theorized and well-executed public library involvement in book scanning and search would look like, this wasn’t it. The original concern motivating the BNF—that Google Book Search was in and of itself a cultural evil to be resisted—never made much sense. Boiled down to its essence, the argument was that Because Google Book Search won’t have enough French works in it, we must not collaborate in adding French works to Google Book Search. As I wrote in my How to Fix the Google Book Search Settlement:
One last point of accountability concerns an issue raised by Jean-Noël Jeanneney: what books are scanned and in the collection at all. Jeanneney’s specific concern—a lack of Francophone sources—has an easy and obvious response: the Bibliothèque nationale de France, of which he is the president, could join with Google to scan its collections. Indeed, Google has indicated its broad willingness to partner with libraries interested in scanning large corpuses of books to get them into the digital collection more quickly.
As the Times reports, though, the French project was massively underfunded:
The decision was purely financial, said Denis Bruckmann, director of collections at the library — which will be joining 29 other leading libraries in opening its shelves to Google’s project, including Oxford’s Bodleian. France provided only €5 million a year for digitising books for Gallica, the national digital library, yet the national library needed up to €80 million (£68 million) just for its works from 1870 to 1940, he said.
Another recent filing, this one from the son of the prolific author Kay Boyle. This one focuses on the Registry, and on whether the AG and AAP have negotiated a deal that’s truly in the interests of individual authors. It has something of a kitchen-sink quality, but here are a few of the issues that struck me as salient:
The attorney filing the motion, Jerome Garchik, has been trying to have himself named as an “independent” director of the Registry. This quixotic campaign (he doesn’t actually ask the court to order that he be appointed) does raise an interesting question: What reasons, if any, must the named plaintiffs give for their choice of Registry board. Legally speaking, the settlement would suggest that the answer is “none,” but pragmatically, I would have thought that the parties would be well advised to announce the intended board now. They have designated an executive director-in-waiting, Michael Healy, who has a good reputation as a forward-thinking metadata technocrat from his work at the Book Industry Study Group. The positive reaction to that choice makes me think that the parties ought to have nothing to lose and a lot to gain by trotting out similarly well-liked board members. If the slate included, say, an academic author and a publisher with library experience, a lot of people would be nontrivially reassured. I pressed on this issue at the Columbia conference in March, but didn’t get much of an answer.
The filing appeals to cy pres principles. Cy pres is the equitable doctrine by which courts are empowered to reform charitable trusts whose original purpose can no longer be fulfilled. The filing suggests that the Registry’s escrow of revenues for orphan works should be viewed through a cy pres lens, which would permit the court to redirect the money to “a related, existing non-profit such as a consumer rights group, a health provider, or a university.” The settlement does already direct that unclaimed funds from Consumer Purchase programs eventually go to charities; I read this filing as trying to make that redirection earlier and more comprehensive.
The filing states, “The Court should insist that membership in either the Authors Guild or the Publishers Association is NOT required for a rights holder to seek royalties from Google via the Registry.” I see no need to worry here; no such clause is in the settlement, so what the filing asks for is already the case.
The filing also insists that the 63/37 split is unfair to copyright owners, pointing to Scribd’s more generous 80/20 split. Perhaps, but I take this to be the virtue of the settlement’s extensive rights owner control provisions; if you like Scribd’s deal better, stay in the settlement and then exclude your works from display uses. (This may be more of an issue with respect to orphan works, but for active rights holders, the 63/37 split is not on its face obviously unfair.) The filing also asks whether side agreements in the Partner Program, on more generous terms, suggest that sophisticated publishers are doing better than the settlement provides. This, in a sense, is William Morris’s core argument: opt out, because you’ll get a better deal in one-on-one negotiations.
The filing spells out some fairly specific guidelines for greater Registry independence from the named plaintiffs, including direct annual elections, and more stringent reporting and disclosure standards.
There’s more of a story with this document’s actual filing than with most. It’s typewritten (you can see where the author made corrections here and there), and it was filed in hard copy. This led the clerk’s office to reject the filing, insisting that it needs to be refiled electronically. (Garchik assures me that he’s about to do just that.) Given the subject matter of the case, I’m amused by the ironies of the attorney’s use of a typewriter and the court’s insistence on e-filing.
GBS: Clerk’s Office Summaries Can Be Misleading
The letter from the members of the University of California Academic Council has hit the court’s docket. The clerk’s summary of the letter is certainly a model of concision:
LETTER addressed to J. Michael McMahon from Mary Croughan, Henry Powell et al, dated 8/13/09 re: Not opposed to the settlement. (cd)
If I had to pick a phrase to describe the letter, “Not opposed to the settlement” wouldn’t be the one I’d choose.
An anonymous comment to this eWeek article points to a newish site on the settlement: The Great Google Book Grab. The site consists of little more than a list of links to negative commentary on the settlement, a little invective (“So what if we’re evil”), and a gallery of creative-but-angry images.
Stylistically, the site has a lot in common withGoogle Watch. It uses the same background color, has the same agitprop sense of humor, is also registered anonymously through Domains by Proxy, and links to a Google Watch page. It has no favicon, though, and there are stylistic differences here and there in the HTML. I’m not willing to rule out the possibility that this is a site run by someone merely imitating Google Watch.
Regular readers of this blog will not find much new at Book Grab, but I pass it along for the sake of completeness.
GBS: Make That Three Authors’ Groups
Now it’s the American Society of Media Photographers, a 6,000-member professional organization, that has concerns about the settlement. I’m not really sure about the specifics, but the ASMP says:
ASMP believes that the proposed settlement has far-reaching consequences for the work product and the livelihoods of its more than 6,000 member photographers, and that the settlement does not adequately protect their interests. Therefore, ASMP plans to submit its views to the Court on or before September 4, 2009, the new deadline for filing objections and other comments.
GBS: Another Authors’ Group Steps Forward
The American Society of Journalists and Authors has issued a statement announcing its plans to file a submission with the court. Interestingly, while the press release’s headline declares that the ASJA “Joins Groundswell of Opposition to Google Book Settlement,” the actual statement is more muted:
The freelance writers’ group is not asking the court to scrap the entire settlement document. Rather, it will ask the court to direct changes in specific sections.
Issues they’ll raise include representation on the Registry board, protections for reader privacy and against censorship, and the removal of deadlines for opting out. I’ll have more detailed commentary when their actual filing itself becomes available.
GBS: The University of California Academic Council Is Worried
The University of California’s library system has been one of Google’s scanning partners. Now another part of the Cal system—the members of its Academic Council—have written a letter to the court expressing concerns about the settlement. (Please don’t ask me to explain the precise role of the Academic Council within the byzantine Cal administration.)
The specific critiques will not be surprising to anyone who’s been following the debate about the settlement. Instead, this is a case in which the letterhead matters; the letter is signed by every last one of the faculty members of the governing body of one of the largest university systems in the country. Due to political reasons only hinted at in the letter, they write only in their personal capacities as professors, but in another sense, that makes the unanimity all the more striking. Anyone who’s worked in academe will attest to the difficulty of herding this many cats.
Here’s the summary paragraph:
We have three main concerns about the proposed settlement agreement. First, to maximize access to knowledge, prices should be reasonable. Unfortunately, the proposed settlement agreement contains inadequate checks and balances to prevent price gouging and unduly restrictive terms for purchasers of books and institutional subscribers. Second, the agreement does not contemplate or make provision for open access choices that have in recent years become common among academic authorial communities, especially with regard to out of print books. The settlement agreement only contemplates that authors would monetize their books and related metadata through the Book Rights Registry (BRR). This is especially worrisome as to the millions of out of print, and likely orphan, books. Third, the agreement contemplates some monitoring of user queries and uses of books in the Book Search corpus that negatively impinge on significant privacy interests of authors and readers and undermine fundamental academic freedom principles.
I found the letter’s discussion of possible responses to pricing abuses particularly interesting:
There are a number of ways that this court could contribute to guarding against the grave risks of future price gouging and other unreasonable terms. One would be to retain jurisdiction over this case so that there would be opportunities for judicial review of the agreement insofar as it resulted in price gouging or other unreasonable terms. The court also could appoint a special master to hear such complaints. A second would be to extend the existing arbitration of disputes provision (Article IX of the settlement agreement) so that institutional subscribers could have a venue for arguing that prices or terms are unreasonable. We are encouraged by the announcement that Google’s agreement with the University of Michigan libraries gives the libraries the right to submit pricing disputes to independent arbitration. A third would be to insist that the agreement be amended to omit the “most favored nation” clause, thus ensuring more robust competition. A fourth would be to supplement the agreement with provisions requiring that academic authors be represented on the BRR governing body. A fifth would be to require the parties to devise and implement better ways to reset prices than a metric that focuses on hypothesizing prices for similar services or products that don’t exist. A sixth would be to amend the agreement so that “unclaimed” funds from public domain and orphan books and books whose owners have not registered with BRR would be used to reduce institutional subscription prices rather than being given to BRR registrants and to nonprofit organizations for purposes of promoting literacy. This last suggestion is a particularly useful example of how the current settlement agreement does not adequately represent the interests of academic authors. As authors, we rely on our ability to use UC’s libraries to do our work. We would strongly prefer that UC’s libraries pay lower fees for institutional subscriptions rather than paying in to funds that the BRR will give to people who do not own rights to the books in question or to charities who may not be members of the author sub-class.
I particularly like the last proposal; it fits with my belief that the best way to deal with funds that remain unclaimed after however many years is to issue refunds. Interestingly, the letter’s view that unclaimed funds should be used to reduce subscription costs arguably finds some support in the provisions of the settlement that allow the Registry to use unclaimed funds to pay its own expenses. It’s possible to argue that using unclaimed funds to pay operating expenses creates cost savings that could be passed along to subscribers. (It’s also possible to argue that the savings will be passed back to the copyright owners instead. The actual economic analysis is tricky, and I haven’t attempted it with any rigor.)
The letter’s second main head—open access—seems to have been squarely addressed by Google’s Creative Commons announcement this week. Academic critics of the settlement had a concern, and Google has promised to give them exactly what they asked for. Yay. Everyone wins.
The letter’s final topic—privacy—is one of the hot-button issues for the public-interest community. The EFF is making privacy the center of its settlement-related campaign, and it seems unlikely they’ll be alone in that respect. The letter provides a nice overview of some of the concerns.
It closes with a carefully modulated statement of where they stand on the yes-or-no question before the court:
In concluding this letter, we want to make clear that we are not opposed to the settlement. As we understand it, the question before the court is whether the settlement is fair to the author sub-class whose interests will be affected by the settlement. This letter argues that the settlement is not equally fair to all members of the author sub-class and does not fully address the needs of academic authors. However, with clarifications requested in our letter, some supplementary provisions to address our concerns, and other amendments, we believe it would be fair enough to academic authors to be approved.
The emphasis is mine; the highlighted sentence does a nice job of fitting the authors’ concerns to the legal question before the court. I see the letter as being sincere in its statement of overall non-opposition. It expresses significant, legitimate worries about the settlement, which it raises in a spirit of improving the settlement, rather than one of scuttling it. Read that last quoted sentence again, though, and read it carefully; its implications are … interesting.
Finally, props to the Academic Council for excellent use of a diæresis.
GBS: The CCIA Jumps into the Fray?
The Computer and Communications Industry Association is apparently even more interested in the Google Book Search case than I realized. Last week, they sponsored the panel at the National Press Club with me, David Balto, and Jonathan Band. Now I see that they plan to file an amicus brief with the court. Their attorney, Matthew Schruers, has moved for admission pro hac vice, a first step along the path to his filing an amicus brief on their behalf. (How do I know they plan to enter as an amicus? Because the caption of the motion refers to them as “Amicus Curiae Computer and Communications Industry Association.” I look forward to seeing what should be an interesting filing.
I blogged earlier in the week about a letter that William Morris Endeavor Entertainment sent to its clients recommending that they opt out of the settlement. Or rather, I should say, I blogged about news stories on the letter, since I couldn’t get my hands on a copy. At the time, I though that William Morris’s stated reasons for recommending opt-out—that the settlement would “bind copyright owners in any book published prior to January 9, 2009 to its terms—seemed unconvincing. The Authors Guild issued a swift, strong reply and even held a conference call for its members to respond.
Well, William Morris has itself responded to the controversy with a new memo, this one apparently intended for public consumption. And this time, we’ve been able to track down a copy, which we’ve added to our collection at the Public Archive. My initial hunch, that the press summaries were misleadingly incomplete, has turned out to be correct. William Morris’s concerns are both much smaller and much larger than the news coverage (and the Authors Guild’s reply) would lead one to believe.
The critical point about the advice letter is that it recommended opting out, not objecting. William Morris has no big beef with the settlement itself. It just believes that its clients are better situated to take advantage of the Google Books program by opting out and striking individual deals with Google than by relying on the settlement’s rules. (In this sense, the Authors Guild may have overreacted, inadvertently transforming a small piece of advice to a few authors into a big dust-up, and making a calm view of the settlement seem like an angry one.)
The reasons for this confidence are interesting. First, William Morris thinks its clients have more negotiating power than the average author does:
We believe that our clients benefit from their stature, the negotiating power of the Agency, as well as long established precedent in our book contracts that other authors may not share.
Perhaps this is over-confidence, perhaps not. My best impression is that Google’s Partner Program is largely a take-it-or-leave-it deal. Google’s ethos is that if it’s not worth doing at scale, it’s not worth doing. Thousands of one-off deals would be unworkable for Google’s machine-heavy, people-light way of doing business.
William Morris’s attitude reflects also a calculated gamble that Google’s proffered terms are unlikely to change for the worse. Since Google seems strongly inclined to offer the same revenue splits and control to copyright owners not included in the settlement class at all (such as the authors of books not yet written), and Google seems inclined to offer the same terms to everyone, this strikes me as a fair assessment of the world. I don’t know that the upside potential really outweighs the foregone inclusion fees, but William Morris’s reasoning here is at least colorable.
The second interesting point William Morris makes is that the “terms of the Settlement are interminable.” (Having read them, I can say, no, it only seems like it.) In particular, William Morris is focused on the non-display uses—such as keeping the books in the search database, algorithmic research, and other large-scale automated processes. If you stay in the settlement and don’t Remove your book within twenty-seven months, you consent to all such uses forever.
Here, things get a little tricky. William Morris happens to believe (as I do) that the non-display uses are fair uses. The Authors Guild seized on this point, writing:
However, William Morris believes Google’s scanning is a fair use (an unusual position for those concerned with authors’ rights, and a decidedly outlier position for those in the copyright bar). What is more confusing is that William Morris encourages authors to opt out of the settlement while at the same time encouraging them to grant Google the right to use digital copies of their works for search purposes.
That’s a fair critique, and William Morris’s reply in its second memo is more of a point about long-term bets in copyright:
As of today, it appears to us that “non-display uses constitute fair use, but it is impossible for anyone to predict that such use will always be the case. And if such inclusion is not fair use, there may come a time when the author or their heirs might wish to remove their work from the Google database for any reason. The authors waive that right, forever, if they do not opt out of the Settlement.
Personally, I think that trying to reason forward about possible mutations in fair use law of this sort is an exercise in creative make-believe, and that there is no point in planing, one way or the other, for shifts of this form.
The third point William Morris makes is, to me, truly fascinating:
Few if any major publishers currently intend to make their “in print” works available for sale through the Settlement program. When it comes to “in print” works, the more restrictive instructions to Google from either the publisher or the author control. This means that if either the author or the publisher does not want an “in print” work sold through the program, Google will not have the right to sell it.
It appears that most major publishers will not allow their “out of print” books to be sold through the Settlement program either. In fact, we believe that most major publishers will take the position that none of their backlist is “commercially unavailable” as defined in the Settlement because the availability of on-demand and other electronic editions will constitute the works as being in print.
Read those two paragraphs again, slowly. If the analysis of post-settlement strategies is right, the implications are large. Let’s go sentence-by-sentence:
Few if any major publishers currently intend to make their “in print” works available for sale through the Settlement program.
If true, then most publishers plan to opt in to the settlement, collect their inclusion fees, and then promptly exclude their books from the Institutional Subscription and Consumer Purchases. That means that these two programs won’t be all that large, and the settlement is in fact not all that big a deal as to in-print works.
When it comes to “in print” works, the more restrictive instructions to Google from either the publisher or the author control.
This is one of the most interesting provisions in the settlement’s description of how copyright owner control will work. I’ve read it as being an author-protection provision; the author can veto the publisher’s attempt to sell a book, and thus possibly negotiate a better deal than the revenue splits specified in the settlement, even where the rights in the book haven’t reverted to the author. But …
This means that if either the author or the publisher does not want an “in print” work sold through the program, Google will not have the right to sell it.
… it’s also a publisher veto program. Publishers can veto all sales, and William Morris thinks that they will. This means that from a practical perspective, authors don’t have much control. Once the publishers say “no” across the board, it doesn’t matter what authors say. This would make many of the detailed provisions in the settlement and the Author-Publisher procedures largely moot. They’re beautifully engineered systems that won’t be used very often.
It appears that most major publishers will not allow their “out of print” books to be sold through the Settlement program either.
I have no idea what the source of this information is, either, or whether it’s true or not. But if it’s right, then the settlement’s two major programs will include few books that being actively managed by their copyright holders.
That means—again assuming that William Morris is right—that the settlement is really only about two classes of books. First, there are reverted books fully controlled by their authors—not a category to sneeze peanuts at, but not where the action in publishing is, either. And second, there are orphans.
I take two implications from this line of reasoning. First, the settlement is in a sense really about the orphans. We would expect almost all non-orphan works either not to be available through Google at all, or to be available through non-settlement terms. The settlement would give Google a license to the orphan catalog, and that’s the major work that it would do. In a sense, the settlement would be a three-way trade. Google gets the orphans and permission to index, authors get some money, and publishers get a renegotiated set of library agreements that put substantial limitations on what libraries can do with their digital copies.
Second, if we’re really being serious about protecting the interests of orphan owners, we can’t use opting in to the settlement as a measure of whether active copyright owners think the deal is reasonable. They could stay in the settlement but then immediately (and permanently) Remove or Exclude their books. That would indicate that they don’t really like the economic terms of the settlement, which would suggest that they haven’t fairly represented the interests of owners who may take a long time to show up.
This says to me that the settlement needs some kind of Removal/Exclusion threshold. If more than some specified fraction of registered (with the Registry) rightsholders choose to Remove or Exclude their books, then all unregistered rightsholders should be presumed to have done the same. This provision would be similar to the opt-out triggers some settlements contain, but based on the fact that the proposed settlement has both external (send a letter to the court) and internal (Remove or Exclude) opt-out provisions. Without this kind of trigger, the incentives of present class members and absent ones are misaligned.
Perhaps William Morris’s analysis of what publishers will do is wrong. It would certainly be easy for some major publishers to make statements about their intentions that would refute William Morris’s predictions. But if they’re right, the settlement looks very different—both a smaller and a bigger deal than it first appears.
If you’re like me, you’re deeply frustrated with PACER, the United States court system’s electronic records service, particularly with its 8-cent-a-page fees. These records are a key component of what Carl Malamud calls “America’s Operating System.” Behind PACER’s paywall are the court decisions that make up “the law” and all of the filings and motions that are our judicial system in action. The fees deter public access, making it harder to know what our courts are doing, alienating Americans from their government.
Well, meet RECAP (that’s “PACER” spelled backwards, although the logo shows a vertical reflection), a new Firefox extension from the wonderful folks at Princeton’s CITP. RECAP is a beautifully clever piece of crowdsourced archiving. Once you install it, it tags along every time you log in to PACER. Download a document, and RECAP ships a copy off to the Internet Archive. When you go to PACER to look up documents, RECAP checks the Internet Archive’s collection and offers to give you a free copy if someone else has already uploaded it.
The great part about this is that because the Archive is providing the server space for free, every RECAP user is saving the court system work. Each time you download through RECAP, you avoid having to go through PACER’s servers at all. So yes, RECAP will mean a decrease in PACER’s revenues, but it also means a decrease in the things those revenues need to pay for. It’s an all-around good thing. It saves attorneys, researchers, and citizens money. It saves the government computer resources. And it makes the law just a little bit more free and accessible.
If you use PACER at all, even occasionally, you should install RECAP today.
GBS: University of California Library FAQ
The University of California Libraries have aposted a FAQ on their ongoing negotiations with Google about becoming a Fully Participating Library. It’s not recent, but I’m just getting around to reading it now. On the whole, it’s highly readable and a very helpful summary of the settlement’s provisions from an academic’s perspective. I liked, to pick just one example, this succinct description of where libraries stand under copyright law:
Libraries own these books in their collections – shouldn’t the libraries be able to make the digital versions available to users everywhere, for free, just as the books themselves are?
Although libraries own the physical copies of these books, many of the works themselves are still protected by copyright. A copyright holder has exclusive rights under the federal Copyright Act, including the rights to reproduce the work or prepare derivative works based on the original. The exclusive rights are tempered by certain statutory exceptions, such as fair use, interlibrary loan, reproduction for use by persons with disabilities, etc., but none would allow the libraries to make whole print or digital copies for users for their free use.
This clear and direct document becomes interestingly evasive in places, though:
Will libraries discard books that have been digitized?
- One of the benefits to libraries is the opportunity to make collection management decisions, especially in light of dimming prospects for increasing physical space, whether on campus or in shared library facilities.
That’s not an answer to the question, and the phrase “opportunity to make collection management decisions” is a little frightening.
- Libraries are studying the best approaches for taking advantage of digital copies, but it is extremely unlikely that all physical copies will be discarded. It is more likely that the digital copies will work synergistically with their physical counterparts, enhancing and extending access to the originals. For example, by making the digital copies accessible through the Institutional Subscription or on a more limited preview basis through Google Book Search or HathiTrust, the millions of volumes already in storage at one of the two UC regional library facilities or located at another UC campus will be able to be consulted online before deciding whether to request a copy for physical delivery, saving users’ time and reducing wear and tear on the physical volumes themselves.
Got that? It’s “unlikely that all physical copies will be discarded.” But discarding all of the copies is a low threshold. The point that consulting electronic copies will often be an effective substitute for bringing in an offsite physical volume is important and legitimate—but “physical delivery” and “discard” are answers to different questions.
- Just as there were experiments and investigations about usage patterns when digital journals became available, there will likely be similar studies to understand how best to meet faculty needs for books, both print and digital.
That’s not an answer, either. If the experience with digital journals is any indication, this sentence suggests that UCL expects the Google Book service to be exorbitantly expensive and to display a great many physical book purchases.
Other sections embrace controversial positions with respect to the settlement. Thus:
What about the view that Google will have a monopoly?
…
The main concern appears to be that Google has a monopoly on the provision of orphan works since others will not have the same protections, absent legislative action. However, Google took a significant business risk in digitizing works regardless of copyright status. Most organizations involved with mass digitization, other than Google, have chosen to avoid digitizing works that are still in copyright. Nothing in the Settlement precludes another organization from scanning works and establishing a comparable service.
This is the same excessively simplistic view of the orphan works issue under the settlement that I have been trying to debunk for the past nine months. The settlement doesn’t block others from competing to sell orphan works … but copyright law does. Google scanned books for different purposes and then coincidentally leveraged it into a settlement letting it sell the books. That road, as I’ve explained at length is not guaranteed to be open to others. They wouldn’t just face “business risk”; it’s illegal for anyone else to do what Google proposes to do under the settlement.
My question for the University of California Libraries is this: If you believe that the post-settlement world is really open to competitors, will you commit to working with them on scanning books, too?
Later on, when speaking of orphan work revenues, the UCL FAQ states:
Another complaint is that the unknown rightsholders will not receive financial benefits; rather, the Registry, the known rightsholders, and selected nonprofit institutions will receive the income if a rightsholder remains unknown (either by name or by address). UC would prefer that all royalties from orphan works go to nonprofit organizations, but we were not a party to the lawsuit. While arguments can be made about the relative fairness of the revenue-sharing scheme, the fact that orphan works will be accessible and usable is beneficial.
I’ve seen this from a bunch of libraries; they want to orphan works revenues go to nonprofits. Sometimes (though usually only in private), they say, “to libraries.” I agree with them that diverting orphan works revenues to the Registry and other rightsholders is problematic, particularly on conflict-of-interest grounds. But the fact of the matter is that if a work is truly and irrevocably orphaned, no one has a good moral claim to the money. Those works ought to be in the public domain.
Once you take the position that the rightsholder is unfindable, the only place the money should reasonably go is back to the reader who paid for it in the first place. The pool of unclaimed orphan works funds are phantom revenue; we should recognize that it came from readers, not from some magical money spigot in the sky. Refunding it back to them doesn’t just fix the corrective justice problem of their overpayment; it also reduces the deadweight losses of charging for access at all. I’m agnostic on how long Google and the Registry should hold unclaimed funds, but not on what should happen to the money once the orphan copyright owner is officially declared lost at sea.
Finally, let me note that if you are interested in questions of equity and access between libraries, you will want to read the item, “What if the price of the institutional subscription becomes unaffordable?” very carefully.
GBS: University of California Libraries Statement
The University of California Libraries, one of Google’s book-scanning partners, are at work on negotiating an amended version of the agreement, much as Michigan, Texas, and Wisconsin have done. The Libraries have posted : a statement codifying some of its “understandings” about the settlement.
The statement runs through a list of eleven issues which are ambiguous or absent in the settlement but the library community cares about. It then explains what UCL “understands” Google to have promised to resolve those issues. In some cases, the understandings cover the concerns pretty comprehensively, e.g.:
(2) In the Settlement Agreement, Google has reserved the right to exclude up to 15% of books from the corpus. Notwithstanding this provision, we understand that
Google does not intend to exclude books of any kind from the corpus for editorial or non- editorial reasons;
Should Google exclude some books for editorial reasons in future, it will publicly post a list of books that are excluded;
The Fully Participating Libraries have the right to take the Library Digital Copy (LDC) of books that are excluded for editorial reasons and make them available through another provider under the same Settlement terms that govern Google as a provider.
In other cases, the document shifts, tellingly, from “we understand” to “we strongly urge”:
(9) With regard to both the commercial and the institutional subscription versions of Google Book Search, we understand that Google is developing standards of confidentiality that will apply to collection and use of personally identifiable data on Book Search usage. We strongly urge Google to adopt strict standards. We also strongly urge the library or libraries that manage the non-consumptive research corpus to adopt the strictest possible standards of confidentiality for all uses of the research corpus and any pertinent products and services.
Of course, with only a few exceptions, neither the “understand” nor the “strongly urge” terms are contractually or judicially enforceable promises. They’re commitments that the library community wants to hold Google to by making it extremely uncomfortable for Google should it try to back off from them. (Salil Mehra, in a fascinating work in progress, is suggesting that the Federal Trade Commission may have an important role to play in making these non-promissory statements of intention enforceable in this and other network effects situations.)
Let me briefly summarize the eleven points, since they’re fairly significant. I’ll leave the actual commitments in roman type, but italicize the “strongly urges.”
Google plans to scan everything it can, rather than deliberately excluding some books.
Google has the right to exclude some books from its services, but doesn’t currently plan to, and will be transparent about it if it ever changes its mind.
“Removal” from Google’s corpus really does mean “removal.”
Google will still push for orphan works reform and will share what it learns about the orphan status of specific books.
Google won’t try to put private restrictions on any public-domain books.
Google will support authors’ and publishers’ choices to make their books open access.
Google will always make book search and 20% preview available for free.
Google will make its library subscriptions work like other subscriptions libraries are familiar with, using similar licensing terms.
Google should adopt strict standards to protect reader privacy.
Google won’t transfer its rights under the settlement without also transferring its obligations.
Google should build in additional pricing safeguards to protect public access and the Registry should transparently represent academic authors and scholarly publishers.
The statement is an important map to the current landscape on the intellectual-freedom, open-access, and public-interest issues of paramount interest to researchers, scholarly publishers, and academic libraries.
GBS: National Writers Union Opposes Settlement
Local 1981 of the United Auto Workers, a/k/a the National Writers Union, has issued a statement opposing the proposed Google Book Search settlement. According to Larry Goldbetter, the NWU’s president:
According to our understanding of the proposed settlement, writers whose copyrights were violated might receive a check for between $60 and $300 for each book and $15 per article. Compared to the number and seriousness of the violations, the amount being offered by Google to each writer is ridiculously low. Also, of the $125 million offered by Google, only $45 million is for writers. This seems way short of the amount needed to compensate authors of millions of books.
Since I thought that the original lawsuits were losers because of Google’s fair use case, I have to disagree. Authors are entitled to nothing in exchange for Google’s scanning, indexing, and snippet display. The $60 a book inclusion fee is found money.
The NWU also opposes the proposed settlement because it would give Google a license to reproduce a writer’s copyrighted work unless the writer specifically tells Google to remove his or her work from the program. This would apply to U.S.-based and foreign writers who might not be aware of the settlement and to those who presume — with good reason because it’s the law — that their copyright protects them without the need to take further action.
This is the opt-in/out-out point that scholars such as Oren Bracha have raised. In a sense, it’s inherent to class action law, so the mere fact of going to an opt-out regime can’t be a winning argument to reject the settlement. Otherwise, class actions in copyright cases would be impossible. One needs some argument why this opt-out is unfair or infeasible. The strongest arguments I’ve heard on that ground, which are hinted at in the NWU’s statement, are deficiencies in notice towards the class and the international implications (since authors from other countries are unfamiliar with United States class actions and have an especially strong tradition of automatic copyright without formalities).
[Finally,] the NWU opposes the settlement because it interferes or might interfere with the relationship writers have with their publishers. The settlement makes assumptions about electronic rights that writers may or may not have assigned to publishers and it sets up an unfair binding arbitration process to resolve disputes between writers and publishers. These disputes must be arbitrated on a case-by-case basis. The settlement does not allow for writers, who were collectively targeted, to collectively negotiate to settle these disputes.
This is indeed one of the most controversial aspects of the settlement: its creation of the Author-Publisher Procedures to reallocate, by fiat, electronic rights in books. Interestingly, more of the suggestions that the reallocation is unfair seem to be coming from the authorial camp than from publishers. It’s possible either that the authors got outnegotiated by the publishers or that the more numerous author class has a longer tail of members whose ox will be gored or who are particularly talkative.
The NWU’s points about arbitration are quite interesting. As a union, it has an interest both in providing an inexpensive forum for its members to achieve redress (arbitration good!) and in being able to negotiate on all its members’ behalf at once (arbitration bad!). I expect to see multiple filings in the weeks to come that focus on defects in the arbitration procedures, to be followed by some counter-filings that play up the virtues of the process.
Tagged.com Sued over Email-Harvesting Chain-Letter Scheme
Wendy Davis, Social Network Site Accused of ‘Harvesting’ Email Addresses:
The California case was brought by Miriam Slater of Santa Barbara and Sara Golden of Los Angeles. Slater, an artist, alleges that she received a Tagged email on June 6 that purported to be from an acquaintance who wanted to share photos.
Slater says in the complaint that she visited the site and provided the company with information, but only because she wanted to view the pictures. She alleges that Tagged never disclosed that she was actually registering to join the site or that it would harvest her email addresses and then solicit those contacts.
Golden alleges that she joined Tagged after receiving an invitation that appeared to have been sent by Slater. Slater and Golden are seeking class-action status. They allege that Tagged’s actions violate various laws including the federal Stored Communications Act and Computer Fraud and Abuse Act.
I haven’t had the chance to think carefully through the legal merits of the various claims, but Tagged’s behavior is slimy. In my forthcoming article on social network privacy, Saving Facebook, I call this sort of tactic a “chain letter,” because it uses manipulative social appeals to convince people to propagate it to their friends. As I write:
We’ve seen that social network sites spread virally through real social network. Once they have, they themselves provide a fertile environment for memes and add-ons to spread rapidly through the social network of users. There’s an obvious network effect at work; the more users a given site or Application has, the more engaging it is.
There’s also an obvious conflict of interest here; Hubert would like Hermes to join him in using HyperPoke, even if Hermes himself wouldn’t enjoy it. Under most circumstances, the network effect and the conflict of interest are inseparable; they’re both irreducibly social, and the best we can do is leave it up to Hubert and Hermes to negotiate any tension between themselves. Most of the actual operations of viral word-of-mouth marketing are necessarily beyond regulation, and should be.
Matters may be different, however, when Hubert has an interest in Hermes’s participation that goes beyond the pleasure of his company. If Hubert is being paid to convince Hermes to sign up, he has an incentive to treat Hermes as an object, rather than as a friend. HyperPoke is subverting the relationship; that’s bad for Hermes and for their friendship. There’s a particular danger that a social network site feature could be “social” in the same way that a multi-level marketing scheme or a chain letter is: by bribing or threatening current users to use every social trick in their book to bring in new ones. …
This is a useful general principle: It’s presumptively illegitimate to bribe users to take advantage of their social networks. True, there’s a fine line between these “artificial” incentives and the “natural” incentives of inherently social Applications, but Facebook is doing the right thing by banning viral incentives that have no legitimate connection to the Application’s actual functionality. Regulators should watch out for the deliberate exploitation of social dynamics, and where appropriate, prohibit such practices.
I was talking about bribery rather than trickery, but the effect is the same. Raiding my address book without my knowledge and then sending out forged invitations under my name involves the same contagious hijacking of people’s relationships and it’s just as abhorrent.
GBS: LULAC Likes the Settlement
The League of United Latin American Citizens has submitted a letter favoring the settlement, citing the same kinds of pro-access arguments that the National Association of Federally Impacted Schools and the American Association of People with Disabilities did. I suspect we’ll see a fair number more such similar letters before September 4. I’d guess that the parties have been making an effort to reach out to groups that advocate on behalf of traditionally disadvantaged communities, emphasizing the settlement’s equalizing effects.
In some important ways, both proponents and critics of the settlement have been obsessed with its distributional implications. Advocates point to the free terminal, the broadly available subscription service, and the various free online uses as opening up the world of books to those who have had to go without a research library collection. Critics worry about the pricing of the institutional subscription being out of reach of all but the richest institutions in their categories. Note that these are, in a sense, the same exact concern. Note, too, that no matter what structure the settlement takes or doesn’t, the rich institutions will always look for ways to parlay their wealth into competitive advantage. The question thus has to be what the actual situation on the ground will look like, given that many are playing the positional game.
GBS: Google Books Adds Creative Commons Licenses
Authors and publishers who make their books available under Creative Commons licenses now have a friend in Google, which just announced that open access is now a reality on Google Books. Not only can you choose to make your book available as a free PDF download, but Google will also mark the PDF and the book result page with your choice of Creative Commons licenses. Here, for example, is Larry Lessig’s Code 2.0. I’ve questioned some of Google’s licensing practices in the past, so it’s a relief to see that the PDFs carry no restrictions other than an explanation of the CC license and a brief blurb about Google Books.
This move directly responds to one of Pam Samuelson’s concerns. As an academic author concerned about open access and academic values, she wanted to make sure that Google’s digital-book programs would respect the wishes of authors and publishers who want to make their books as widely available as possible, rather than just maximizing revenue. Congratulations to Google for listening to her concerns and adding this principled, useful, and public-spirited new feature.
GBS: Mark Lemley’s Antitrust Analysis
Mark Lemley’s An Antitrust Assessment of the Google Book Search Settlement has been online at SSRN for a month and no one told me? Come on, folks, step it up!
There’s not much new in this short piece. I thought there were three interesting passages. First, on market definition:
First, it is strange to talk about a “monopoly” over an ill-defined set of books. Nobody knows which books are actually orphaned. Furthermore, the term “monopoly” is usually applied with respect to an economic market for a good and its substitutes. Orphan works seem unlikely to constitute a separate market, because many if not all will contain comparable content to non-orphaned books.
That sounds right; orphan works, as such, are probably not a distinct market. Their significance in the more general market(s) for books is open to empirical debate, of course.
Second, on legal barriers:
A more interesting argument is that no one can duplicate Google’s effort because anyone who did so would face a lawsuit similar to the one filed against Google. Even assuming that this is the case, it is not clear that the fact that Yahoo! or Microsoft would have to face the same risk Google did should change the analysis. Much of the criticism of the Google Book Search settlement seems to stem from a belief that Google’s use of the books was a fair use and so not an act of copyright infringement. For what it’s worth, I agree. There is nothing to prevent Yahoo! or Microsoft from litigating the same case to judgment, winning, and then being able to digitize the works and show snippets without paying the price Google has paid. Nothing would prevent them from attempting to negotiate the same or similar terms in a settlement. Of course, doing so is risky, because the statutory damages rules (mistakenly, in my view) threaten not just compensation but dire punishment if the defendant gets it wrong. But Google faced the same risk; it is more than a little odd to say that Google violates the antitrust laws because it has a monopoly that arises solely from the fact that it is more willing to take chances than its competitors.
This mischaracterizes the situation. If Google obtains a monopoly, it will not be solely because it was willing to take more chances than its competitors. Google has shown boldness in scanning books, asserting fair use in indexes and snippets, and negotiating for a full-access settlement. But the final, essential ingredient will have been the use of a class action lawsuit blessed by a court. All the boldness in the world can’t get Google to the Institutional Subscription without a judge’s signature on an order compromising away the rights of copyright owners. It’s an exercise in chutzpah to claim that Google deserves unprecedented access to books because of the risks it took in demanding unprecedented access to books.
The objection, then, must be not that Google shouldn’t be allowed to provide a valuable new service, but that others should be able to provide it too. Fair enough. But that’s hardly a reason to object to the settlement.
My problem is not with the settlement; it’s with certain terms in the settlement. The exclusivity of the settlement’s authorizations is not an essential feature; if the parties were motivated to solve the antitrust issues, they could fix the exclusivity problems. There’s a reason our amicus brief is neither in support of nor opposed to the settlement. As I’ve said from the start, I come to fix the settlement, not to bury it.
GBS: Looking at Privacy Through the Lens of the Security Standard
Eric Hellman has an interesting post, What the Google Books Settlement Agreement Says About Privacy. He provides a lot of context on how libraries currently implement security and deal with privacy issues with other electronic databases. He also reads the settlement’s security provisions in some detail, and manages to back out from them some specifics about what privacy could and couldn’t look like for the subscription service the settlement sets up.
GBS: The American Association of People with Disabilities Likes the Settlement
They praise the settlement’s effects in making accessible versions of books available. I’d note that most of the disability-specific benefits of the settlement are merely fixes to broken features of copyright law, which is absurdly stingy when it comes to the rights of the disabled. Still, getting the Authors Guild (whom you may remember from their Kindle text-to-speech snit fit) to go along with these expanded access provisions is no mean feat on Google’s part.
Ironically, I’ve been unable to find an accessible version of the AAPD’s letter to the court.
GBS: William Morris Recommends Opting Out
Another data point in an interesting trend; the settlement’s strongest critics in the publishing world are agents. The New York Times quotes from a memo William Morris sent to its clients saying the settlement would “bind copyright owners in any book published prior to January 9, 2009 to its terms.” The Authors Guild is up with a strong reply emphasizing authors’ flexibility under the settlement and negotiating power.
Without a copy of the memo itself, it’s hard to say much more. The very limited summary the Times provides doesn’t strike me as terribly convincing, but the quotes from William Morris attorney Eric Zohn on searchability are smart, and suggest that there might be more there there. If any Lab readers have a copy of the memo, please get in touch.
GBS: What About That Secret Termination Agreement?
The proposed Google Book Search settlement contains a termination clause:
Google, the Author Sub-Class, and the Publisher Sub-Class each will have the right but not the obligation to terminate this Settlement Agreement if the withdrawal conditions set forth in the Supplemental Agreement Regarding Right to Terminate between Plaintiffs and Google have been met. Any decision by Google, the Author Sub-Class or the Publisher Sub-Class to terminate this Settlement Agreement pursuant to this Article XVI (Right to Terminate Agreement) will be in accordance with the procedures set forth in the Supplemental Agreement Regarding Right to Terminate. The Supplemental Agreement Regarding Right to Terminate is confidential between Plaintiffs and Google, and will not be filed with the Court except as provided therein.
A termination clause is a standard element of contracts and settlements. But this one is a little unusual: it’s secret. The “Supplemental Agreement Regarding Right to Terminate” is a deal between Google and the class representatives (the Authors Guild, the Association of American Publishers, and five each of individual authors and publishers). No one else even gets to look at the termination agreement:
The Supplemental Agreement Regarding Right to Terminate is confidential between Plaintiffsand Google, and will not be filed with the Court except as provided therein.
One of the commenters at the Public Index, Gillian Spraggs, asked:
What about the rest of the settlement class? If this document is part of the settlement agrement, surely they have a right to see it?
It’s a very good question. How can members of the plaintiff class properly evaluate whether the settlement is in their interests if the whole thing can be revoked under conditions and by procedures that are kept secret from them? How can the court evaluate whether the settlement is fair and reasonable without knowing what kind of doomsday triggers it contains?
I’m sure that Google and the named plaintiffs will say, “There’s nothing dangerous in there; trust us.” And indeed, it might consist of nothing more threatening than an opt-out threshold. But then again, it might not. Unless the termination agreement is opened up, there’s no way to tell.
GBS: Pam Samuelson: The Audacity of the Google Book Search Settlement
Looks like it’s the first in a multi-part series on the Google Book Search settlement from one of its most prominent academic skeptics:
Sorry, Kindle. The Google Book Search settlement will be, if approved, the most significant book industry development in the modern era. Exploiting an opportunity made possible by lawsuits brought by a small number of plaintiffs on one narrow issue, Google has negotiated a settlement agreement designed to give it a compulsory license to all books in copyright throughout the world forever. This settlement will transform the future of the book industry and of public access to the cultural heritage of mankind embodied in books. How audacious is that?

{kind=link}
Marty Scwhimmer on a Powerade/Gatorade ad dispute:
Ha! Take a look at who Pepsi and Coke pay to endorse the product. Look at the ads. Spend time with thirteen year old boys. These products thrive on unreasonable consumers relying on unjustified beliefs.
I’ll be speaking at two lunchtime events next week, both panel discussions on the Google Book Search settlement. I’ll be at the National Press Club on Tuesday the 11th, as part of a panel featuring David Balto and sponsored by the CCIA. Then, on Wednesday, I’ll be at the Princeton Club, on a panel presented by the New York chapter of the Copyright Society of the U.S.A. Both events are by reservation only, so book early and book often.
GBS Blogging: When the Unprecedented Becomes Precedent
I participated last Friday in a Berkman Center workshop on the Google Book Search settlement and the open-access roads not taken. In my remarks, I tried to sketch out the possibilities the settlement itself might open up to advance open access goals through future class-action settlements. It came across a little bit chaotically; there turned out to be quite a lot to say. I’ve gone back to my notes and written up an extended version, an essay I’m calling When the Unprecedented Becomes Precedent: Class Actions in a Google Book Search World:
Some people concerned about the proposed Google Book Search settlement, including me, have complained that the settlement is a ticket good for Google only. Google gets a set of copyright licenses that would be difficult to obtain through traditional negotiations—and effectively impossible in the case of orphan works. No one can compete on equal terms; the public at large can’t take full advantage of the orphan works Google has access to.
Google has consistently replied that anyone is free to do what it has done: scan books and seek a class-action settlement. I’ve expressed public skepticism about this claim, noting that there’s no legal right to such a settlement, only an uncertain prospect of seeking one. I’ve also worried in private that the settlement is so precisely tailored to Google’s circumstances that even the same exact deal would be of little use to anyone else.
But what if I’m wrong? What if others could obtain their own Google-style settlements without fuss? If the Google settlement were on the books, what other settlements would be on the table? What rights could Google’s competitors obtain to books; what could open access advocates do for other works?
This brief essay is an attempt to answer those questions by turning the settlement inside-out. Rather than focusing on what makes the Google settlement unique, I’ll examine what it would take to replicate it. David Balto has argued that the Google settlement would be a “precedent” for future, similar settlements. If so, then we should treat it the way that lawyers are trained to evaluate precedents from the first day of law school: by asking which of its features of it are essential to its precedential value, and which could be changed the next time around.
As always, I welcome your reactions.
Go Away or I Shall Taunt You a Second Time
The Associated Press has issued a statement explaining the “license” they gave me to quote Thomas Jefferson. A few brief comments:
It is an automated form, thus explaining how one blogger got it to charge him for the words of a former president.
The problem is not just that they use an automated form to issue their “licenses” (although the automated form does make it easy to mock them). No, the problem is that they also make bizarre, sweeping copyright claims about “their” content. Their automated form is a trap for the ill-informed, and the rest of the AP is doing yeoman’s work to keep the quoting public ill-informed.
As the AP stated more than a year ago, the form is not aimed at bloggers.
I am a blogger, but the “license” fees they charge would be equally absurd for any medium. It’s just as much fair use for a Fortune 500 company to quote a half-dozen words from an AP story as it is for a blogger. The public domain is open to everyone. The form is a lie, and saying “We’re not lying to bloggers” is merely a way of ducking the true issue.
It is intended to make it easy for people who want to license AP content to do so.
As applied to short excerpts and material not taken from AP stories (think about the user who’s trying to quote from two stories and enters text from the non-AP one by accident), no license is required. In this context, “mak[ing] it easy to license AP content” in that context means making it easy to send the AP money by mistake.
I just got an automated email from iCopyright, the flunkies who handle the AP’s insane blog licenses. It turns out that my “license” to quote Thomas Jefferson has just been “revoked” and my money refunded. When I saw that word, all I could think of was Danny Glover’s response to the bad guy’s claim of diplomatic immunity Lethal Weapon 2: a bullet and the quip, “Just been revoked.”
Oh, noes! Does this mean I need to take the Jefferson line down? Will they sue me for infringement and cattle rustling if I don’t? Whatever will I do now that the all-knowing AP won’t permit me to use twenty-six words by a man who’s been dead for a hundred and eighty-three years?
I love it. The AP realizes it’s made a mistake trying to assert copyright over words it didn’t write and doesn’t own, but it can’t even bring itself to admit it. No, they’re saying they’ve “revoked” the license, as though it were their choice whether to allow me to quote Jefferson in the first place. How about this, AP? Why don’t you buy a “license” from me that allows you not to be such dunderheads when it comes to copyright? I’m willing to give it to you for free if you’re interested—but somehow I don’t think you are.
The AP Will Sell You a “License” to Words It Doesn’t Own
The Associated Press has become so deranged, so disconnected from reality, that it will sell you a “license” to quote words it didn’t write and doesn’t own. Here, check it out:

I paid $12 for this “license.” Those words don’t even come from the article they charged me 46 cents a word to quote from (and that’s with the educational discount). No, they’re from Thomas Jefferson’s letter to Isaac McPherson, in which Jefferson argues that copyright has no basis in natural law.
Does that stop the AP? No. They tell me I have to use the sentence “exactly as written” and heaven help me if I don’t include the complete footer with their copyright boilerplate. Along the way, their terms of use insisted that I’m not allowed to use Jefferson’s words in connection with “political Content.” Also, I can’t use use his words in any manner or context that will be in any way derogatory” to the AP. As if. Jefferson’s thoughts on copyright are inherently political, and inherently derogatory towards the the AP’s insane position on copyright.
I require no license to quote Jefferson. The AP has no right to stop me, no right to demand money from me. All their application does is count words to calculate a fee. It doesn’t even check that the words come from the story being “quoted.”
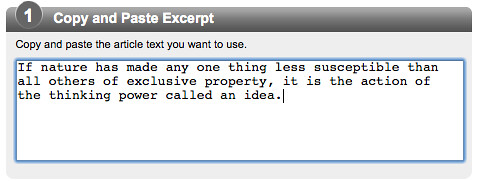
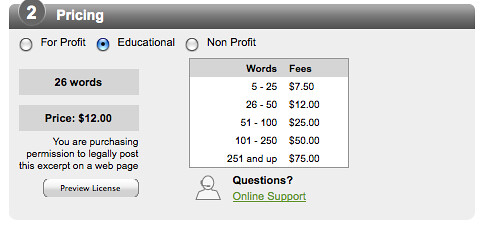
Is it any wonder the AP also tries to deceive bloggers into thinking it’s not fair use to quote five words? Their abuse of the public domain is just the reductio ad absurdum of their abuse of fair use. The whole thing is a vile species of copyfraud.
Update: License revoked.